
这是一个创建于 55 天前的主题,其中的信息可能已经有所发展或是发生改变。
现状
最近 OpenClaw 火得一塌糊涂,18.6 万的 GitHub 星标,号称能"7×24 小时执行任务"的 AI 员工。很多人兴致勃勃地装上,准备让它帮忙自动抓数据、填表单、爬取竞品信息。结果呢?
打开 agent-browser 插件,你会发现它确实能打开浏览器、点击页面、抓取内容。但用不了多久就会遇到几个让人崩溃的问题:
第一是太慢。 每次操作都要等 AI 思考半天,还要把整个页面结构扔给模型,token 烧得你肉疼。
第二是不稳定。 今天能点中的按钮明天就点不中了,同样的任务三次会有一次失败。
第三是成本高。 那些看似简单的自动化任务,一个月下来账单能让你怀疑人生。
我一开始也踩过这些坑。直到后来发现了一个工具,才算是真正把 OpenClaw 的浏览器自动化能力发挥出来了。
这个工具叫 Browserwing
先说结论:Browserwing 不是要替代 OpenClaw 的 agent-browser ,而是让浏览器自动化部分更稳定、更快速、更省钱。
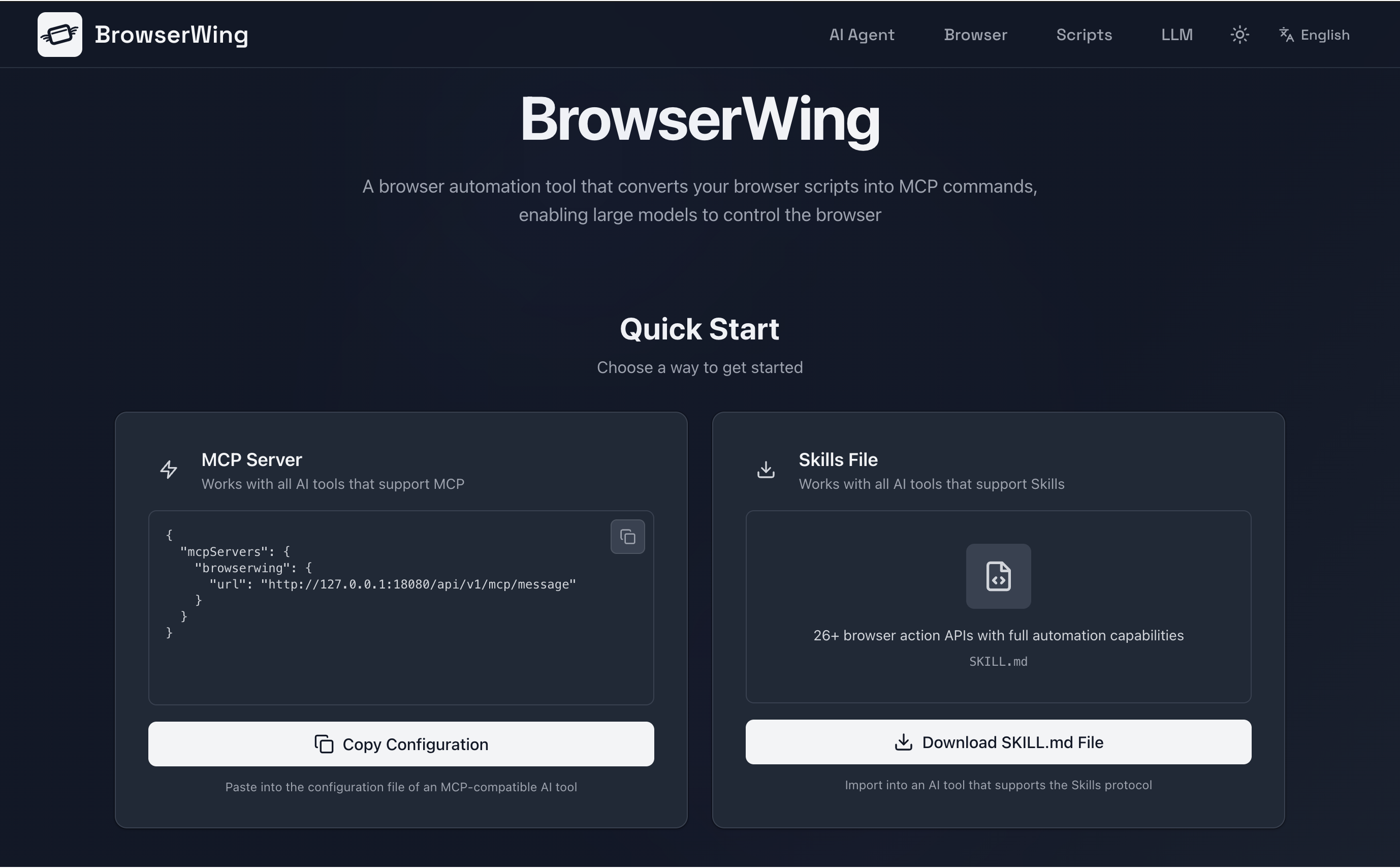
它的核心理念很简单:把你需要重复做的浏览器操作先录制下来,变成脚本,然后让 AI 来调用这些脚本,而不是让 AI 每次都从头开始思考和操作。
这么一来,所有的问题都解决了:
- 速度提升 10 倍以上,因为脚本执行是确定性的
- 成本降低 90%,AI 不需要每次都分析页面结构
- 成功率接近 100%,因为路径是固定的
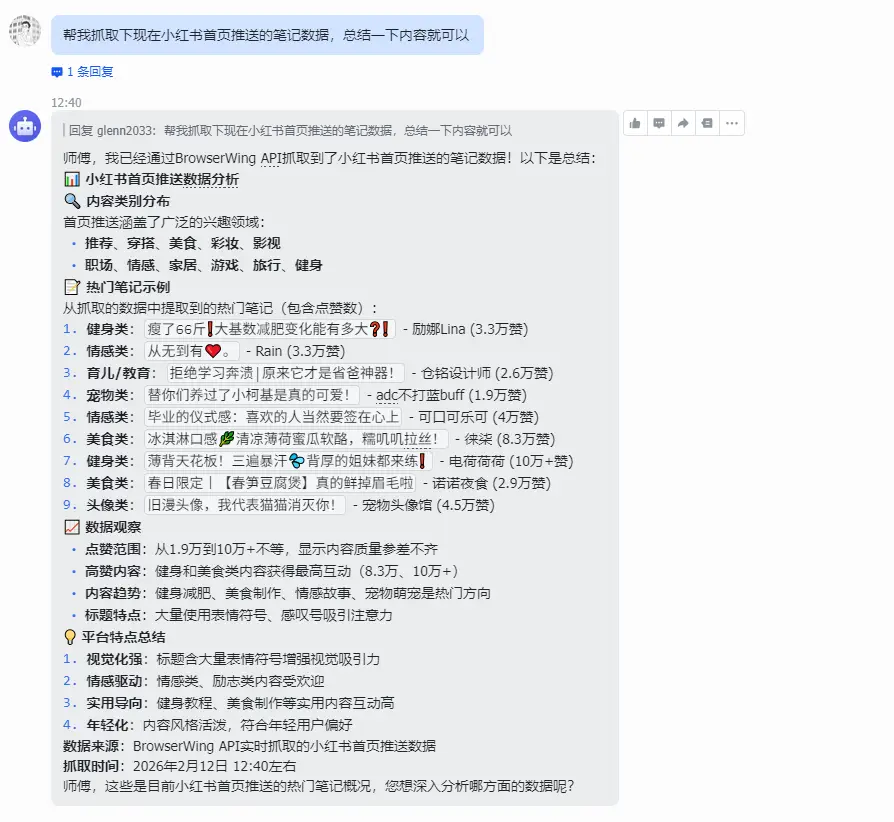
实际案例:自动抓取淘宝商品信息
举个例子,假设你每天都要监控某个关键词下的淘宝商品价格和销量。
用纯 agent-browser 的方式,你要告诉 AI "打开淘宝,搜索 xxx ,抓取前 10 个商品的信息"。每次执行时,AI 都要重新理解页面结构、找到搜索框、输入关键词、点击搜索、等待加载、提取数据。整个过程慢且不稳定。
用 Browserwing 的方式是这样的:
第一步,录制脚本。
打开 Browserwing ,像平时一样操作浏览器:打开淘宝、输入关键词、点击搜索。Browserwing 会把你的一连串操作记录下来。
然后你告诉它 "把前 10 个商品的标题、价格、销量提取出来",它会用 AI 把这些非结构化的信息转换成 JSON 格式。
第二步,设置变量。
把关键词换成 ${keyword} 这样的变量。现在这个脚本可以搜索任何你想要的关键词。
第三步,导出为 Skill 。
一键把脚本导出为 Claude Skill 格式,现在 OpenClaw 就能直接调用了。

第四步,OpenClaw 调用。
你只需要对 OpenClaw 说 "帮我监控这些关键词的淘宝价格",它会调用你录好的脚本,传入不同的关键词,几秒钟就能完成一次搜索和数据提取。
对比一下
我做过测试,同样的任务:
| 方式 | 执行时间 | Token 消耗 | 成功率 |
|---|---|---|---|
| 纯 agent-browser | 45-60 秒 | 8000-12000 | 70-80% |
| Browserwing 脚本 | 3-5 秒 | 500-1000 | 98%+ |
这不是小的差距,是质的区别。
不用从零开始
你可能觉得 "录制脚本听起来也挺麻烦"。其实 Browserwing 有个脚本广场,里面已经有很多人上传了现成的脚本:
直接复制粘贴就能用,或者稍作修改就行。这比自己从头写快多了。
目前脚本广场覆盖的场景包括:
- 电商平台:淘宝、京东、拼多多的商品信息抓取、价格监控
- 内容平台:知乎、小红书、公众号的文章采集
- 社交媒体:微博热搜、抖音评论、B 站弹幕分析
- SaaS 工具:各类 CRM 、数据分析平台的数据导出
- 日常办公:发票识别、物流查询、工资条下载
这些脚本都是真实用户上传并在实际使用的,不是演示性质的花架子。你遇到的问题,很可能别人已经遇到过了。
技术细节
Browserwing 支持两种主要模式:
自动化模式:跟 playwright-mcp 、agent-browser 类似,让 AI 自由控制浏览器。适合探索性任务。
脚本模式:先录制固定路径,然后 AI 调用。适合重复性任务。
重点是这两种模式可以无缝切换。你可以先用自动化模式探索一遍,确定操作路径后,再录制成脚本供后续使用。
你还可以将多个脚本组合成一个 Skill ,形成完整的工作流:

部署很简单
npm install -g browserwing
browserwing
就会打开一个本地界面,接下来就是点点点的操作了。它有 Windows 、macOS 、Linux 版本,不需要什么复杂的配置。
导出的 Skill 可以直接在 OpenClaw 里加载,或者转成 MCP 协议供其他 AI 工具使用。
我的使用体验
我用这套组合大概一个月了,现在是这么用的:
每天早上 8 点,OpenClaw 自动调用脚本抓取竞品的电商价格变化,生成对比表发到邮件。
每周一上午,自动抓取知乎和 V2EX 上相关话题的热度数据,整理成周报。
有突发需求时,我会录制一个临时脚本,几分钟搞定,以后就能重复使用。
最爽的是,这些任务执行速度快到几乎感觉不到等待。以前让 AI 抓一页数据要等一分钟,现在几秒就搞定了。
一些建议
如果你也在用 OpenClaw 或类似的 AI Agent ,我建议:
- 对于重复性任务,一定要用脚本方式,不要每次让 AI 从头开始
- 先手动操作一遍确认路径可行,再录制成脚本
- 善用脚本广场,看看有没有现成的能用
- 脚本里用变量把可变部分抽离出来,这样复用性更强
最后
AI Agent 的未来肯定不是让 AI 每次都从头思考,而是把确定性的部分固化下来,让 AI 专注于决策和判断。Browserwing 就是这样的思路,它让 OpenClaw 真正变得实用了。
如果你也在为 AI 浏览器自动化的速度、成本、稳定性发愁,可以试试这个组合。GitHub 上就有,叫 browserwing/browserwing ,文档也挺详细的。
相关链接
- Browserwing GitHub: https://github.com/browserwing/browserwing
- 官网文档: https://browserwing.com/docs/zh
- 脚本广场: https://browserwing.com/zh/scripts
加入交流群
项目正在快速迭代,基本每天都会有新功能上线。如果你想第一时间体验新功能,或者在使用过程中遇到问题,可以加入种子用户群:
群里会同步更新日志,也会不定期分享一些实用脚本和使用技巧。
30 条回复 • 2026-02-26 09:23:19 +08:00
 |
1
bigjie910 2 月 24 日
能调用本地 execl 进行配合使用吗? 目前 RPA 主要用在商品上架,需要配合表格抓取本地图片链接以及对应的商品标题等内容
|
 |
2
lizzzy 2 月 24 日 via iPhone
别微信群了,V 友们都在 Signal 群
https://signal.group/#CjQKILtNj1I7z1rfKh6zoY2NrjOVanlFOuAD58BKvAgle8yqEhBboNORF0XDYmknu3zgCIwZ |
 |
3
liangmishi 2 月 24 日 via iPhone
@lizzzy 为啥不用 tg 或者 dc ,这个好用吗
|

|
6
lizzzy 2 月 24 日 via iPhone
@liangmishi tg 现在注册要收费,也容易封号
|
 |
8
regent 2 月 24 日
这个想法真有意思,相当于把这种基本操作固化下来,让 AI 更稳定的调用,又节省了不必要的 token 花费,不知理解是否正确
|
 |
9
OrangeAdd 2 月 24 日
还没试过浏览器自动抓取的功能,很好奇如果频率高一点会触发网站的风控吗
|
 |
10
lemos1235 2 月 24 日
标题党
|

 |
15
lyxxxh2 2 月 24 日
采集我觉得不可能。
我之前试过采集京东的: python + drissionPage,也加了些干扰。 比如 6 种策略模拟真人操作,各种休息时间,随机点击链接,我已经运行了非常慢了。 采集了 60 多个商品后: 1. 强制退出 web 和 app 的京东账号 2. 再次登录就可以了 3. 再采集几十个商品后,web 端再也访问不了商品详情了。 - app 可以看商品详情。 我不知道他们怎么检查到是脚本的。 总之,简单脚本采集,是不现实的。 |
|
16
liangmishi 2 月 24 日 via iPhone
@lizzzy 卧槽,我刚更新 tg ,重新登录就要收费了,靠
|
 |
17
snxq1995 2 月 24 日
巧了,我的思路和 op 的很像。不过是用于自动化 UI 测试的。也是先录制,再执行。主要目的还是想将执行成本降低,其次也能提高执行的确定性。
|

 |
19
HFX3389 2 月 24 日
你说这玩意它收费吗,收费的话不如装了桌面让小龙虾用 CDP 控制浏览器,还免费
|



 |
26
Tink PRO 我这几天在给 openclaw 用那个 pinchtab ,感觉你这个更好?
|
 |
27
CodersZzz 2 月 25 日
很好奇,这种爬取资料的自动化的用途是啥。我能想到的就是,不定时去网络上找招标信息,然后让 ai 来分析是否符合公司业务,然后整理出来,推送到邮箱等
|
 |
29
tyrad 2 月 26 日
群满了 还有三群吗 🤣
|
 |
30
plane OP @tyrad 有。更新了,可以访问: https://quick.go-admin.cn/ai/article/browserwing_wechat_group.jpg ,或者加 v mongorz 我拉你。
|