V2EX = way to explore
V2EX 是一个关于分享和探索的地方
Sign Up Now
For Existing Member Sign In
• 请不要在回答技术问题时复制粘贴 AI 生成的内容

写在开头
FBI Warning⚠️:如果您没有使用过 ai 工具,没有相关的编程经验,或是对这个话题不敢兴趣,请您现在就退出当前页面。它将浪费你人生中宝贵的三分钟
友情提示:如果你想设计一个自己的 agent 或者想要深入理解 agent 如何高效运行,那么花 10 分钟理解本文会是你今年迄今为止对自己的时间做出的最值得的投资
想象一个项目工程,是做加法容易?还是减法容易?做一个通用 agent ,如何兼顾所有用户需求?如何能在简洁的前提下让一个有智慧的 agent 充分自举?
- GitHub: https://github.com/juntao-ai/GenericAgent
- 论文: https://arxiv.org/pdf/2604.17091
- 教程: https://datawhalechina.github.io/hello-generic-agent/
1. 核心问题:Agent 为什么跑着跑着就变蠢了?
做过 Agent 开发的应该都遇到过这个现象:Agent 在前几轮表现不错,但随着对话轮次增加,它开始丢约束、忘指令、重复犯错。
作者把这个问题归结为两个根本挑战:
挑战一:上下文爆炸。 每一轮交互都在往上下文里塞东西——工具定义、历史对话、工具返回值、检索到的记忆。这些内容在产生时各有用途,但对"下一步该做什么"的贡献参差不齐。无关内容不是被浪费那么简单,它会主动稀释模型的注意力,导致约束遗漏和幻觉。
挑战二:经验停滞。 如果 Agent 无法把成功经验沉淀下来,每次遇到类似任务都得从头探索。token 花了一堆,能力纹丝不动。作者管这叫 Stagnation Loop 。
这两个挑战的交汇点指向一个核心问题:LLM 的上下文到底应该塞什么?
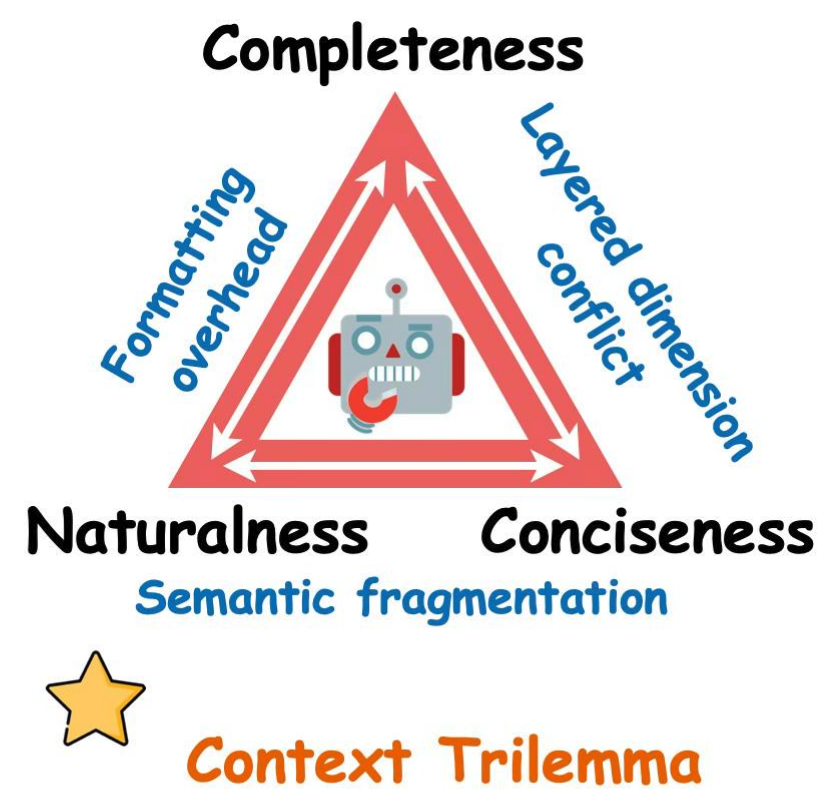
2. 第一性原理:上下文信息密度最大化
GA 给出的答案是一个形式化的设计目标:
D(C) = 决策相关信息量(C) / 上下文总长度(C) → max
翻译成人话:不追求上下文的长度,追求每一个 token 对当前决策的贡献密度。
这个目标拆开来看有两个维度:
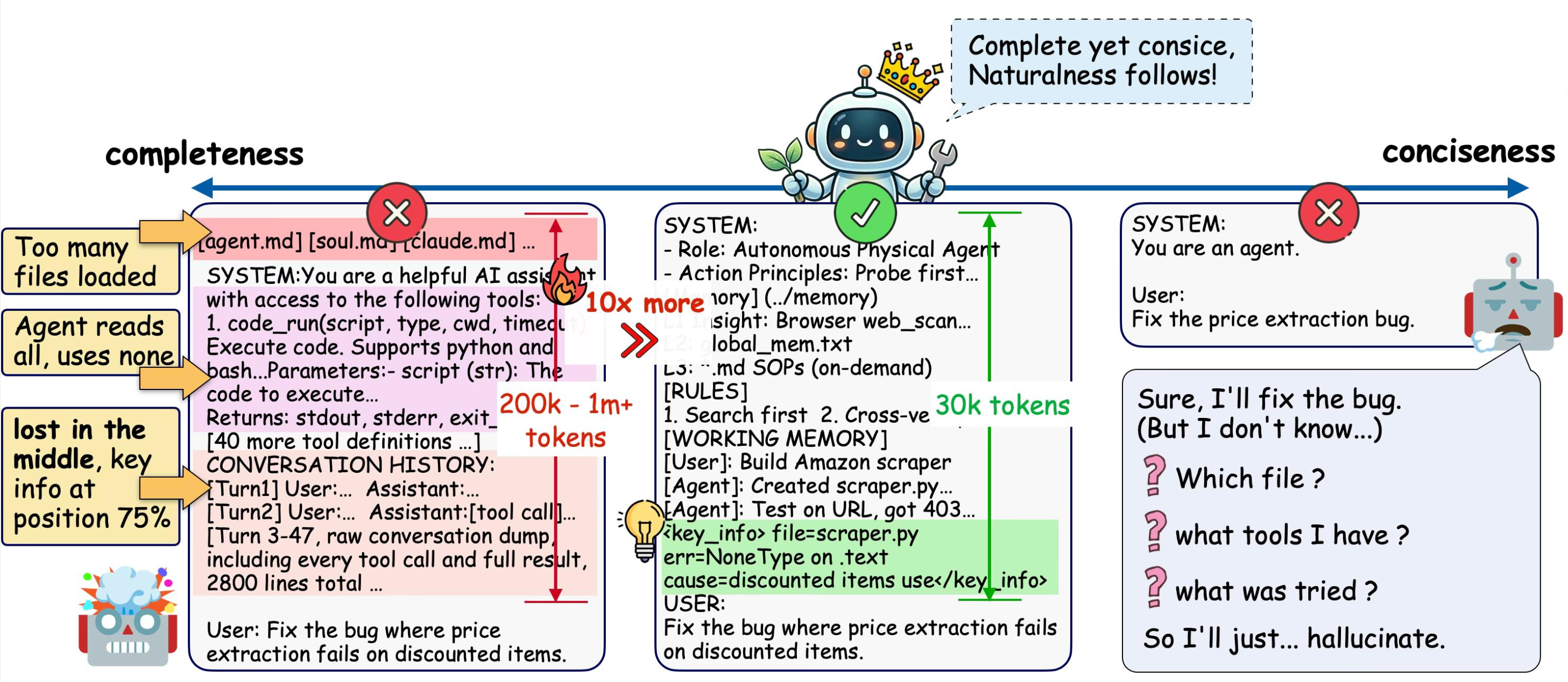
- 完备性( Completeness ):当前决策需要的信息必须显式出现在上下文中,不能让模型靠猜。
- 简洁性( Conciseness ):无关和冗余的信息必须清除,让注意力聚焦在关键信号上。
作者提出了一个关键洞察:完备性和简洁性之间的张力是结构性的,不是资源问题。 即使上下文窗口无限大,这个矛盾依然存在——因为加入更多"可能相关"的信息提升了完备性,却必然稀释注意力(削弱简洁性);而压缩提升了简洁性,却有丢失关键细节的风险(削弱完备性)。
所以 GA 的所有设计决策,本质上都是在这个结构性张力下做约束优化。
3. 为什么"上下文越长表现越差"——三重陷阱
这不是 GA 自己编的结论,是多篇论文验证过的现象。作者总结了三重相互强化的失效模式:
-
位置偏差( Lost-in-the-Middle ):LLM 对上下文开头和结尾的信息利用率高,中间部分容易被"遗忘"。关键信息落在中间位置时,模型可能直接忽略。
-
注意力稀释( Attention Dilution ):注意力是有限资源。无关内容越多,分配给每条关键信息的注意力越少。无关内容不是被浪费,而是主动干扰。
-
有效窗口远小于名义窗口:一个标称 128K 的模型,真正能稳定推理的有效窗口可能只有几万 token 。随着上下文增长,推理能力逐渐退化。
这三者形成恶性循环:上下文膨胀 → 注意力稀释 → 位置偏差加剧 → 有效窗口收缩 → 系统倾向于注入更多"可能有用"的内容来补偿 → 上下文进一步膨胀。
核心启示:超过某个临界点后,增加更多上下文不仅无法提升性能,反而会降低表现。
4. GA 的系统性解法:四层信息密度优化
GA 不是靠一个 trick 解决问题,而是在信息生命周期的四个阶段分别做优化:
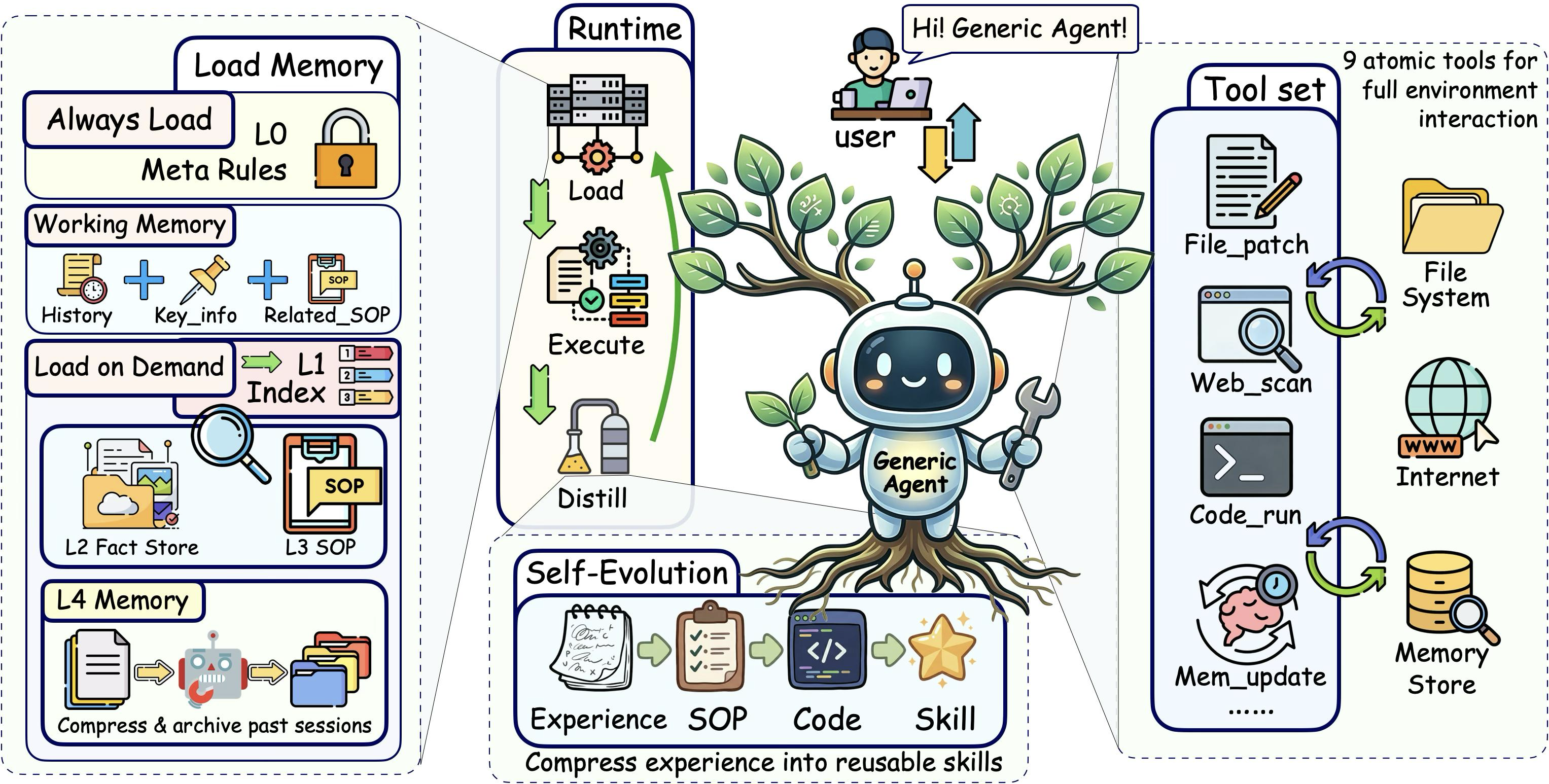
4.1 最小原子工具集——减少"先天噪声"
工具定义是上下文中每轮都要重复支付的固定成本。GA 的策略是极端克制:只保留 9 个原子工具。
为什么不是越多越好?作者指出工具膨胀有两层代价:
- Prompt 层:每增加一个工具,就要在上下文中注入 Schema (名称、描述、参数类型)。53 个工具的 Schema 可能消耗上万 token ,而且每轮重复。
- Policy 层:工具越多,动作空间越大,选择歧义越高。比如"读文件"这个操作,如果同时有 FileReadTool 、GrepTool 、BashTool(cat),模型需要理解三者的微妙差异才能正确选择。
GA 的 9 个工具覆盖五大能力类:文件操作( file_read / file_write / file_patch )、代码执行( code_run )、网页交互( web_scan / web_execute_js )、记忆管理( update_working_checkpoint / start_long_term_update )、人机协作( ask_user )。
关键设计:code_run 是万能逃生舱。任何 9 个工具覆盖不到的长尾需求,都可以通过写代码来实现。这意味着工具集不需要为每个边缘场景增加专用工具——保持了工具层的极简,同时不牺牲能力上限。
code_run 本质上是图灵完备的!
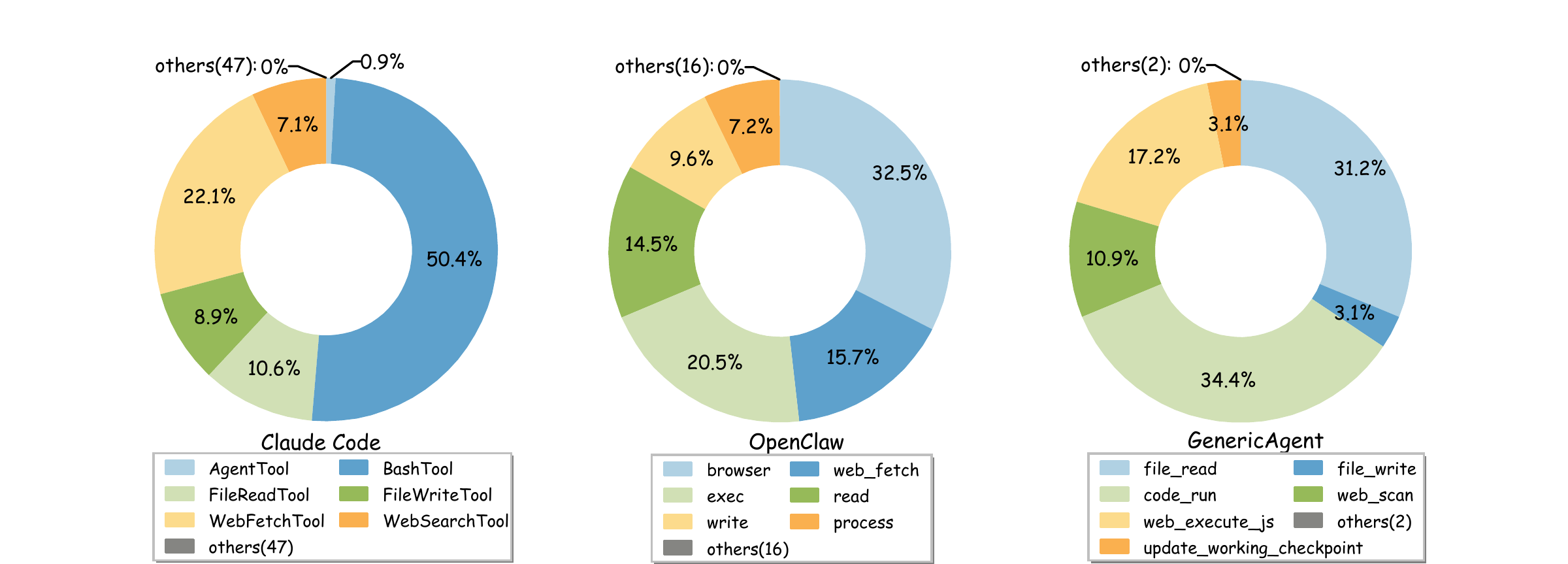
实际使用分布(论文数据):code_run 34.4%、file_read 31.2%、update_working_checkpoint 17.2%,三个工具覆盖了 82.8% 的调用。
4.2 分层按需记忆——只加载"当前需要的"
传统方案要么不保留历史(每次从零开始),要么全量追加(上下文爆炸)。GA 用了一个四层架构:
| 层级 | 定位 | 是否 always-on | 典型大小 |
|---|---|---|---|
| L1 索引层 | 目录卡片,告诉 Agent "有哪些知识可用" | 是 | ~200 token |
| L2 事实层 | 环境事实、用户偏好、服务器信息 | 否,按需 file_read | 数百~数千 token |
| L3 SOP 层 | 标准操作流程、技能脚本 | 否,按需 file_read | 每个 SOP 数百 token |
| L4 原始日志 | 完整对话历史,用于追溯和审计 | 否,极少访问 | 无限增长 |
核心机制:L1 始终在上下文中(成本极低),L2-L4 只在需要时才被加载。 这就像图书馆——你不会把所有书搬到桌上才开始工作,而是先查目录( L1 ),再去书架取需要的那本( L2/L3 )。
作者的消融实验验证了这个设计的有效性:
| 记忆配置 | 记忆大小( token ) | 任务成功率 TSR |
|---|---|---|
| No memory | 0 | 52.44% |
| Full memory (全量注入) | 575 | 52.44% |
| GA 分层记忆 | 165 | 66.48% |
165 token 的分层记忆达到了 575 token 全量注入的 1.27 倍成功率。 全量注入反而跟没有记忆一样——因为无关信息稀释了注意力。这是"上下文越长表现越差"的直接实证。
4.3 上下文截断与压缩——主动瘦身
即使工具和记忆都控制住了,对话轮次增加后上下文仍会膨胀。GA 用四阶段压缩流水线处理:
- 工具返回值截断:code_run 输出超长时只保留头尾
- 历史轮次压缩:早期对话轮次被摘要化
- 消息驱逐:超出预算的最旧消息被移除
- 工作记忆锚点注入:通过
update_working_checkpoint工具,Agent 主动把关键中间状态写入一个始终可见的锚点,防止被压缩丢失
第 4 点是个巧妙的设计——Agent 自己决定什么信息值得"钉住",而不是靠启发式规则猜测。
4.4 反思驱动的自我进化——让未来的上下文更精炼
GA 能把成功的任务经验蒸馏为 SOP 存入 L3 。下次遇到类似任务时,不需要在上下文中重新探索整个解决方案,直接调用之前积累的精炼经验。
这解决了"挑战二:经验停滞"。没有进化机制时,Agent 面临两难:要么重放更长的探索过程(削弱简洁性),要么从更短但信息不足的提示词开始(削弱完备性)。自我进化打破了这个两难——把冗长的探索轨迹压缩为紧凑的可复用知识。
5. 架构实现:92 行的 Agent Loop
GA 的主循环只有约 92 行,结构是标准的 perceive-think-act:
while not done:
context = assemble(system_prompt, always_on_memory, tools, history)
response = llm.chat(context)
if response.has_tool_calls:
results = execute(response.tool_calls)
history.append(results)
else:
done = True
整个系统由 4 个文件构成:agent_loop.py (主循环)、ga.py (工具实现)、agentmain.py (入口 + 前端适配)、llmcore.py ( LLM 调用封装)。总计约 3300 行。
这个极简架构的好处是:没有隐藏的复杂度。没有事件总线、没有调度守护进程、没有专用子 Agent 管理器。子 Agent 并行、定时任务、看门狗监控这些"高级功能",全部通过 9 个基础工具的组合涌现出来。
6. 约束下的涌现:三个原语长出整个生态
这是 GA 设计中我觉得最有意思的部分。
传统框架做高级功能的方式是"功能内置":需要子 Agent ?加一个 SubAgent Manager 。需要定时任务?加一个 Scheduler Daemon 。需要事件驱动?加一个 Event Bus 。每个新功能都带来新的接口、新的配置、新的故障模式。系统复杂度线性增长。
GA 走了另一条路:不内置任何高级功能,只提供三个足够通用的原语,让高级行为从组合中涌现。
三个基础原语
| 原语 | 本质 | 一句话描述 |
|---|---|---|
| 自托管 CLI 入口点 | Agent 就是一个命令行程序 | 任何能调用命令行的程序都能调用 GA——包括 GA 自己 |
| 文件协议 | 目录约定的跨进程通信 | input.txt 送任务、output.txt 流结果、reply.txt 续对话、stop.txt 终止 |
| 反射模式 | 轮询 + 热重载 | 外部脚本定义触发条件,运行时周期性求值,脚本修改后自动重载无需重启 |
涌现出的高级行为
子 Agent 并行分发:父 Agent 通过 code_run 启动自己的另一个实例,传入不同的 task-dir 。父子是同构进程——不存在特权的子 Agent 运行时对象,双方遵循完全相同的文件协议。上下文天然隔离(独立进程 = 独立内存空间),不需要复杂的状态管理来区分"哪些历史属于哪个子任务"。
看门狗监控:反射模式 + 一个检测环境变化的触发脚本。当脚本返回非空字符串时,该字符串被作为任务分发到标准流水线。不需要专门的监控框架。
定时任务调度:反射模式 + 一个检查时间条件的触发脚本。跟看门狗共享完全相同的底层机制,区别仅在于脚本内容。
自主空闲行为:反射模式 + 一个"当前无任务"的触发条件。Agent 在空闲时自动执行预设的探索或维护任务。
为什么这能工作
这里的"涌现"不是物理学意义上的不可预测——而是工程意义上的:当基础组件足够通用且组合成本足够低时,设计者未预先规划的功能可以在需要时被轻松实现。
关键不在于"意外",而在于"低成本"。传统框架每加一个高级功能需要修改核心代码、添加新模块、更新文档。GA 只需要写一个触发脚本或一段 code_run 调用——核心代码一行不改。
作者给出的数据:GA 核心代码 3300 行( Agent Loop 仅 92 行),而实现了子 Agent 并行、看门狗、定时调度、自主行为等全部高级功能。作为对比,OpenClaw 的代码量约 530,000 行——160 倍以上。这不是说代码少就一定好,但它说明了一件事:当原语选对了,复杂行为不需要复杂实现。
7. Benchmark 数据
作者在 WebArena 、OSWorld 等标准 benchmark 上做了评测(数据来源:论文 Table 5 ):
| 指标 | GA |
|---|---|
| 总 Token 消耗 | 188,829 |
| 任务成功率( TSR ) | 66.48% |
Token 消耗对比(同一组任务):
| 系统 | Token 消耗 | 相对 GA |
|---|---|---|
| GA | 188,829 | 1x |
| Claude Code | 538,207 | 2.85x |
| OpenClaw | 633,498 | 3.35x |
完整提示词长度对比(安装 20 个技能后,对 "Hello" 的响应):
| 系统 | Full Prompt Length ( token ) |
|---|---|
| OpenClaw | 43,321 |
| CodeX | 23,932 |
| Claude Code | 22,821 |
| GA | 2,298 |
8. 从 Prompt Engineering 到 Context Engineering
作者提了一个我觉得很有价值的视角转变:
- Prompt Engineering 优化的是"一句话怎么说"
- Context Engineering 优化的是"每一轮对话中,模型看到的所有信息应该是什么"
在 Agent 场景下,上下文不只是用户指令,还包含工具定义、历史对话、记忆内容、工具返回值等多种组件。如何系统性地管理这些组件的注入、压缩和替换,才是决定 Agent 长期表现的关键。
GA 通过工具层、记忆层、压缩层和进化层四个维度,把 Context Engineering 落实为具体的系统机制。这不是一个 prompt 写得好不好的问题,而是一个系统架构问题。
9. 我的使用体感和局限
用了一段时间后的观察:
- 上下文 30K 的硬限制是双刃剑。 好处是 Agent 不会因为对话太长而变蠢;代价是单轮无法处理超大文件,需要分段读取。
- 记忆系统完全基于文件,没有向量检索。 SOP 数量特别多时,L1 索引的命中率可能下降。但对于个人使用场景(几十个 SOP ),目前没遇到问题。
- code_run 是万能的,也是危险的。 能执行任意代码意味着安全性完全依赖部署环境的隔离。
- SOP 质量很重要。 写得好的 SOP 能让 Agent 一步到位;写得不好的会误导。这是一个需要用户投入的地方。
- 多 Agent 协作通过进程 + 文件实现,没有结构化通信协议。 简单场景够用,复杂协作场景调试不太方便。
10. 总结
GA 的核心贡献不是某个具体的 trick ,而是一套完整的设计哲学:在完备性与简洁性的结构性张力下,通过四层机制系统性地最大化上下文信息密度。
它证明了一件事:Agent 的能力上限不取决于上下文能塞多少字,而取决于在有限 token 预算里,能装进多少真正对当前决策有用的信息。
如果你正在做 Agent 开发,不管用不用 GA ,它的设计思路都值得参考——特别是"信息密度"这个视角,对 prompt 设计、记忆系统设计、工具集设计都有直接的指导意义。
项目地址: https://github.com/juntao-ai/GenericAgent 论文: https://arxiv.org/pdf/2604.17091 教程: https://datawhalechina.github.io/hello-generic-agent/
写在最后
在上一个帖子发出后,受到了广泛的关注,深感荣幸,所以火速加更!



贴几条热心的 v 友对我善意的人身攻击,我深刻的认识到了我的不足,并意识到自己 too young too simple ,sometimes naive 。
我做出如下承诺: 1 、今后只写提示词,不写文章。 2 、在提示词中要求文章内容去学术化,去叽里咕噜化,去指标化。 3 、更广泛的听取大家的批评,了解 V2EX 的社区规范,学习落实 v 站大佬的悉心教导。保证做到:“余立侍左右,援疑质理,俯身倾耳以请;或遇其叱咄,色愈恭,礼愈至,不敢出一言以复;俟其欣悦,则又请焉。故余虽愚,卒获有所闻。”
另外再回复一下这条:
 本人再次重申,本人为某 top3 高校在读博士,大模型方向,于 3 月中旬刚刚恢复单身,欢迎感兴趣的异性 v 友留下联系方式,谢谢!
本人再次重申,本人为某 top3 高校在读博士,大模型方向,于 3 月中旬刚刚恢复单身,欢迎感兴趣的异性 v 友留下联系方式,谢谢!
最后附上上面这篇文章的提示词:
欢迎大家用 ga 写点公众号文章或者软文吹 claude code 和 codex ,给自己挣点外快!
Supplement 1 · 18h 8m ago
附上第一篇帖子地址 https://www.sunp.eu.org/t/1211200?p=1#reply96 ~
大家感兴趣的话可能对某个技术实现进行再深挖~
大家感兴趣的话可能对某个技术实现进行再深挖~
 |
1
c0xt30a 16h 17m ago
可能有点 OT ,但是我很好奇文中 " top3" 高校是哪个 " top3"
|
 |
2
WillieYang 15h 13m ago via iPhone 上一个帖子就有人问为何故意贴出个人信息,搞了半天真的有相亲意向,还真是推广相亲两不耽误。
何意味? 专业的人要做专业的事,这个道理,OP 工作了以后就会懂了。 我也不想爹味教育,我只是一个夜来闲极无聊的中年老登罢了。 |
 |
3
utodea 12h 31m ago
|
 |
4
HTravel 11h 37m ago 直接说浙大博士不就完了嘛,当然最好本硕也是,否则又是普本给自己贴金。没必要饶
|
 |
5
fbu11 11h 10m ago
浙大哪个学院的?这么折腾是为了写论文?
|
 |
6
h4nru1 OP |
|
7
h4nru1 OP @WillieYang 1 、相亲是我个人生活,跟帖子技术内容有什么关系?我乐意放就放呗,又没求你帮忙介绍。2 、"专业的人做专业的事"——所以你觉得分享开源项目不专业?那 V2EX 创意工作者节点一半帖子都不专业了。3 、爹味教育就免了,中年老登的人生经验我暂时用不上 hhh
|
|
8
h4nru1 OP @utodea 好问题。GA 的自进化核心确实是 memory ,但跟 Codex 的 memory 机制有本质区别:Codex 的 memory 是用户手动写的静态规则(类似 .cursorrules ),本质是 system prompt 注入; GA 的 memory 是分层的( L0-L4 ),agent 自己在执行任务过程中总结经验、发现规律、记录 SOP ,下次遇到类似场景自动调用。简单说就是一个是你教它,一个是它自己学。另外 GA 的多 agent 不只是并行执行,还有监察者( verify_sop )交叉验证,plan 模式拆解子任务,这些组合起来才是完整的自进化闭环
|
 |
9
merkle2222 10h 59m ago
可以试下在记忆层加一个证据 通过证据时间和信息可信度 来优化记忆
可以看下我的这个 fork 改过的 claw https://github.com/mingzhi1/metaclaw |
 |
10
hihanley 10h 36m ago [那么花 10 分钟理解本文会是你今年迄今为止对自己的时间做出的最值得的投资]
[本人再次重申,本人为某 top3 高校在读博士,大模型方向,于 3 月中旬刚刚恢复单身,欢迎感兴趣的异性 v 友留下联系方式,谢谢!] |
 |
11
YAZAKI 10h 20m ago
 问了下 ChatGPT 。ChatGPT 给我的答复。( op 别来喷我,可以自己去问下 ChatGPT 大家为什么对你这么大恶意) |
 |
12
Bad0Guy 10h 19m ago via iPhone @WillieYang 这人只能说喜欢炫但是实际上他自己脑子里装的就那点皮毛,真正目的还是挂那一句相亲的东西
|
 |
13
lswlray 10h 11m ago
OP 不要太在意歪楼跟帖的,V2 早已不是当年的 V2 了,这种情况很常见。
言归正传,我有一个需求: 某企业发现在 JD 、PDD 、TB 等电商网站有自己的产品低价出售,所以希望: 1 、自动搜索并记录这些商品页面;对应的店铺名称和地址;店铺的商家信息、如果是企业的话还要获取对应的工商信息; 2 、自动下单并记录订单信息(订单号、价格、时间、物流单号、是否签收); 不知道你说的这个能否实现?主要是这些电商网站有反爬虫壁垒、获取商家信息也有验证码壁垒,能否稳定解决。 如果可以实现,你是否愿意帮助这个企业来做?可以的话,我可以帮你介绍需求方。据我在这个行业中的了解,应该不止目前这 1 家企业有这样的需求,而是会有很多企业都有类似需求 |
|
15
h4nru1 OP @lswlray 自动搜索+采集信息完全没问题,自动下单没试过。ga 的浏览器策略能够完美避开反爬,但是验证码可能无法开箱就解决,需要研究专门方案。但是总体而言我觉得需求难度不大。在 ga 群里,我看过有人把它改造成电商后台管理,非常好用
|
|
16
h4nru1 OP @merkle2222 L4 的记忆是有时间记录的,但是信息可信度,我的观点是假如你是用模型判断的,那专门额外标一个这个就好像得不偿失,假如是规则判断的,好像规则又挺难写的,而且在使用过程中不一定靠谱
|
|
17
merkle2222 10h 3m ago
不要用一个 llm ,多个 llm 协助
|
|
18
merkle2222 10h 1m ago
成本低的 llm 跑简单任务,优先的 llm 跑具体推理
|
 |
19
ChiangKaishek 9h 59m ago
@Livid AI 生成内容 以及不友善
|
|
21
h4nru1 OP @ChiangKaishek 具体指出不友善的地方。ai 生成请给出检测方法和检测结果。
|
|
22
h4nru1 OP @YAZAKI 1 、幸存者偏差:智力正常的人只会在看完我的文章后立即去 github 点星,尝试运行项目,并陷入深深的思考,思考下一代的 agent 应该是什么样的。我只是一面镜子,照出的是你自己的样子。2 、一开始我只是随意打字吐槽,结果遭受到人身攻击和小圈子的霸凌,为什么我不能回击(但是并未采用人身攻击的方法) 3 、我并没有看到很多恶意,还是有很多人在认真阅读我的文字内容。一个人能看到什么是由自己的认知决定的
|
|
23
YAZAKI 9h 47m ago
@h4nru1 #14 我用什么工具不重要,我只是想让 AI 分析一下大家为什么要指责你,因为我看到的是:op 上一篇文章中说:GA 的技术报告,里面有些 insights 我非常喜欢,而且我的风格也是用数据说话。现实并没有通过数据视角和、完备性与简洁性的结构性张力下,通过一系列机制系统来分析 [论坛网友为什么对你恶意这么大这个现实] 。如果人来主观分析,可能会带有较大的主观倾向,但是 Agent 来的话可能会好一点(不一定要 gpt ,你也可以试着用 GA 来分析,然后通过技术报告或者用数据说话)
顺便说一下:文章中的 GitHub: https://github.com/juntao-ai/GenericAgent 论文: https://arxiv.org/pdf/2604.17091 教程: https://datawhalechina.github.io/hello-generic-agent/ 1 、github 链接 404 2 、本篇文章疑似是洗稿 https://github.com/datawhalechina/hello-generic-agent/blob/main/docs/part2/chapter7/index.md 的内容(大家注意甄别) |
|
24
lswlray 9h 47m ago
@h4nru1 #14 如果只是自动搜索和采集信息,其实有很多解决方案,他这需求特殊,就是在于需要自动下单并记录订单信息。听说他们试过小龙虾是可以的,但不是很稳定,所以你是否愿意尝试一下?或者我介绍你们认识、由他们承担成本、你来研究尝试?
|
|
25
h4nru1 OP @merkle2222 子 Agent 并行分发:父 Agent 通过 code_run 启动自己的另一个实例,传入不同的 task-dir 。父子是同构进程——不存在特权的子 Agent 运行时对象,双方遵循完全相同的文件协议。上下文天然隔离(独立进程 = 独立内存空间),不需要复杂的状态管理来区分"哪些历史属于哪个子任务"。可以通过--llm 传入模型名,实现多模型 agent 协作。这是在约束下涌现的又一例子,ga 本身没有特意为了这个写硬性的模块或者功能
@YAZAKI 感谢批评,对我很有价值。我会在下个帖子承认错误并公开向你道歉(我想通过这个方式表达我对我之前言语上过失的歉意)。那么多人骂我,居然没人发现我的 github 链接点不开 hhh @lswlray 你可以自己先用一下试试,我感觉如果小龙虾能用,基本上换 ga 的浏览器的策略就能秒杀了。这钱自己先挣了 hhh |
 |
26
SWALLOWW 9h 38m ago
感觉仍然 cc 解决复杂任务的思路,多开会话解决注意力问题,以及如何在下一个会话中恢复继续任务的问题
|
 |
27
Charlie17Li 9h 36m ago
|
 |
28
dummyx 9h 34m ago 第一次见开源项目的英文/中文 README 是写在同一个 markdown 里边分不同 section 的。。。
|

|
32
YAZAKI 9h 31m ago @h4nru1 #22
1 、认知优越感式表达 2 、反击本身没问题,但是采用的是“认知压制式反击”,既然是技术贴,那你可以用技术回应或者选择无视 3 、如果把所有 disagreement ,都解释成:“你认知不够”。那讨论就无法成立。既然是技术论坛发帖,就应该允许 disagreement ,你可以选择回应,那就应该选择让人可以信服的反击手段,而不是情绪宣泄式的。 |
|
33
YAZAKI 9h 28m ago
@lswlray #24 我有兴趣研究一下,我有一个小小的技术团队(大概十人左右,具备产品、研发、测试、Agent 工程师),对你说的这个场景比较有兴趣,或许我们可以私下讨论一下。
|
 |
36
a594195609 9h 2m ago
@dummyx 雀食
|
|
37
h4nru1 OP |
|
39
h4nru1 OP @YAZAKI 握手,技术归技术,态度归态度,之前确实我的问题。你们团队如果用 GA 二开有任何问题可以直接 @ 我
@dummyx 中英 README 写一个文件里确实不太规范,不过这项目就一个人维护,精力有限,能跑就行的阶段。。欢迎 PR 拆分 @Charlie17Li 。。 |
|
40
WillieYang 8h 39m ago @h4nru1 这就是不专业的地方,好好推广就好好推广,突然穿插一个相亲介绍的信息,何意味?不知道的还以为是压抑久了,就算压抑久了,跑到一个技术论坛里面找对象也是搞笑,或者你单独开个关于生活的帖子也行,不然下面这么多人喷你,很难说会有女生主动加你。搞这么多骚操作,主要的推广目的也难达成,这不是不专业是什么?除非你的主要目的是找人喷你,那么恭喜你,你的目的达成了。
|
|
41
h4nru1 OP @WillieYang 不同的人能看到不同的东西,你只能看到相亲那两行,怪我咯?
模型的注意力也就是被这样稀释的。 考虑到这里中年程序员偏多,确实不适合相亲。所以在下个帖子我会详细公开我对老丈人的选拔标准。 |
 |
42
GeruzoniAnsasu 8h 16m ago > 欢迎大家用 ga 写点公众号文章或者软文吹 claude code 和 codex ,给自己挣点外快!
何意味,我写了你们会有推广费用? |
|
43
WillieYang 8h 10m ago @h4nru1 哈哈哈,你要不要看你在说些什么?你是在对自己公开处刑吗? “中年程序员”, “不适合相亲”,“老丈人的选拔标准”。从这些话里面,就可以看出你平时的为人处事了。Btw ,V 站年轻人肯定是不少的,互联网就发展这么些年,大多数 V 站老哥我可以说都比你年轻。你自己在这输出一大堆,何意味?
|
|
44
h4nru1 OP @WillieYang 你不是一直在给我盖楼吗兄弟?
|
|
45
h4nru1 OP @GeruzoniAnsasu 生活是生活,工作是工作,business is business 。ga 这么便宜好用,cc 和 codex 流量这么大,用 ga 写点 cc 和 codex 的软文赚点外快不香吗?
|
 |
46
MuyuQ 7h 57m ago
agent 的自进化都会遇到一个问题,新 skill 改变了决策优先级,导致旧流程被改动。
以前可以搞定的任务,因为新 skill 的加入,突然就不会了。要排查就要去面对庞大的历史对话记录。 用的越久,越容易遇到。 自动的分层记忆也有这个问题。如果 agent 自己总结出现了细微的错误(毕竟不是完整上下文),把某段记忆插入了不合适的场景,会导致旧流程被改动。 太多的项目,都喜欢把优点夸大,感觉 agent 是一个完美的自学者。 |
|
47
h4nru1 OP @MuyuQ 非常好的问题!这个问题点出一个重要的问题就是技能冲突(我的猜想这个问题的解法可能类似传统信息检索领域的知识冲突)
首先,回到 agent 的 skill 本身,什么是 skill ?各家的答案都不同,从 a➗的 skill-creator 对 skill 的定义来看,skill 是一个对大模型渐进式披露的项目工程( skill.md+code+assets ),skill 本身就是有结构的。但是我个人对 skill 的看法是,只有模型不知道的事,才值得写进 skill (和 boirs 的看法一样,以后的 skill 和 agent 框架只会越来越短、约束越来越少)。 那么实际上这里所谓的新的 skill 造成的冲突,表现形式我目前能想到的有两种: 1 、环境变化造成的冲突,那么应该立刻更新原有 skill 并将变更写进日志 2 、同目标,多 skill 造成的冲突。可能你有好几个 skill 都是在做 code_review ,但是 agent 无法靠先验知识进行选择。那么技能的评估就非常重要。最近我看到有一篇 skill-X 的论文在做这方面的工作,虽然他提的 training free GRPO 非常之扯,但是也体现这样的趋势。 看到就回了,手打回复,思维有点乱,见谅 |
|
48
MuyuQ 7h 23m ago
@h4nru1 不止是 skill 的冲突。skill 和 skill 的冲突是最好解决的。 问题是 skill 和 memory 的冲突,和 workflow 的冲突,memory 和 workflow 的冲突,时间长了哪儿哪儿都可能冲突。 整了一堆名词一堆工程化手段,说白了还是打补丁。现在折腾这么多,还是没办法搞定 agent 的长期行为约束,真让它全自动学习,崩坏是迟早的事儿。
|
|
49
h4nru1 OP @MuyuQ skill 和 memory 的冲突是索引( memory 中对该 skill 的记忆)冲突吗?这个只能在框架上做同步,就是 skill 有了更新之后,memory 也要对应更新。假如把 skill 当作原子,那么 workflow 会是 skill 的组合(虽然很多 skill 也是 workflow 的形式存在),那我想这时候对 skill 的改造就需要依据你的 workflow ?最起码要保证在 workflow 中的接口对齐?
|
 |
50
zhaohua 7h 6m ago
我最近在项目中使用 mastra ,我觉的和 mastra 比,ga 是个人玩具。
|
|
52
MuyuQ 6h 50m ago
@h4nru1 不止是索引冲突。
是更大范围,更深层的冲突。 memory 可能是错的、过期的、过度泛化的。 skill 也可能只是某次局部成功经验。 workflow 是谁定义的,什么时候该稳定,什么时候该更新? 所以这不是 skill 和 memory 同步一下就能解决的问题。 真正难的是:skill 、memory 、workflow 都会变化,而且还会互相影响。 适用范围怎么定?过时怎么判断?权重怎么分配?冲突时谁正确?这些都不是靠模型临场判断能稳定解决的。 所以还是得靠人工判断,而不是自主迭代。 Agent 倒是可以定时做一次自检,把可能冲突的地方展示给用户,让用户判断。(但自检开销巨大) 我也就瞎想了一下。 吃饭去,吃饭去。 |
|
54
MuyuQ 6h 35m ago
@h4nru1 反思的前提是他自己知道错了,而且知道错在哪儿。
很多任务并不是显式报错。可能在 Agent 看来没问题,反而会强化错误经验。 很多任务可能末端报错,实际错误点在中端,但 AI 只凭感觉修改了末端症状。(这个在 AI 编程中太常见了,agent 也难免) 没有可靠反馈和人工审查,反思很容易变成 agent 自我确认或者末端打补丁。 以目前大模型的能力,人工介入在所难免,人工智障 agent 需要人工导师时不时盯着。 |
|
56
h4nru1 OP |
 |
57
CS200185 5h 5m ago
关于文中所述 “上下文越长表现越差” 中的第一点:Lost-in-the-middle ,我有一些疑问。
这个观点是 https://arxiv.org/pdf/2307.03172 这篇文章提出的。但它是 23 年 7 月成稿的,它做的实验还是 gpt-3.5 那一代的模型。那么这个 “缺陷” 是否有被持续的证实呢。即具体到目前而言,GPT5.5 和 Qwen3.5-27B 这些目前最强的闭源大参数量模型和开源小参数量模型,是否仍然存在 Lost-in-the-middle 的问题。 如果有,能否展示一下相关的论文和实验。如果没有,那么这个 “第一重陷阱” 是否站不住脚呢。 希望 OP 抽空解惑 |
|
58
h4nru1 OP @CS200185 好问题,认真回答一下:
1. Lost-in-the-middle 在新模型上确实有缓解。Anthropic 和 OpenAI 都在训练阶段加了位置均匀采样,GPT-4 turbo 之后的模型在 NIAH (Needle-in-a-Haystack) 测试上基本能做到全位置召回。 2. 但"缓解"不等于"消除"。NIAH 是单针检索任务,实际 agent 场景是多步推理+多信息融合。2024 年 RULER benchmark (arxiv 2404.06654) 测了多针检索和逻辑链任务,即使 GPT-4o 在 128k 时性能也有明显下降。 3. 更关键的是,即使模型"能找到"信息,长上下文带来的注意力稀释仍然影响推理质量。这不是 lost-in-the-middle 一个现象能概括的,而是 attention 机制的固有特性——O(n²) 的 softmax 分布在 n 很大时必然更平坦。 所以帖子里的表述可以更精确:不是"找不到"而是"推理质量随上下文长度单调递减"。GA 的分层记忆本质上是在做信息压缩,让模型在有限注意力预算内拿到最相关的上下文。 |
 |
60
teaguexiao 1h 51m ago
信息密度这个角度很有意思,归根结底就是“把有限的 token 预算用在对当前决策真正有用的地方”,这和人写代码时多开了个文件效果一样。
|
|
61
h4nru1 OP @teaguexiao 对,本质就是这个。不过"多开个文件"这个类比可以再延伸一下:人多开文件是主动选择的,agent 的难点在于自动判断当前决策需要哪些上下文、什么时候该去翻记忆什么时候该现查。GA 的做法是把这个判断也结构化了——通过记忆层级( L0-L4 )让 agent 知道"去哪找"而不是每次都全量灌进去。
|
 |
62
limyel 1h 47m ago
我看到 op 主回应相亲的那个只觉得挺幽默,感觉挺有意思的😂
|
|
63
h4nru1 OP @limyel 哈哈那条确实是即兴发挥,agent 帮我筛完简历我就顺手让它分析了一下相亲对象的朋友圈,结论是"信息密度不足,建议 pass"。开玩笑的,GA 还没接入微信朋友圈(暂时)。
|

|
66
h4nru1 OP @coefu 我说的每句话都有对应的技术实现和开源代码可以验证,你要质疑具体哪个技术点我奉陪。至于我是 top 几的、导师是谁,跟这个帖子讨论的内容有什么关系?
|
 |
67
coefu 55 mins ago
你这么搞的适得其反,你这个也不是大家刚需的非 GA 不可,大把竞品。你逞一时嘴快,网上嘴炮赢了别人又如何?但是你这个项目,因为你盛气凌人的态度,把看法由你而引申到你的 GA ,恰恰起了反作用。本来中立的人,也会考虑考虑了。
别人蛐蛐你,你当然可以反击,如果只是生活区为了某个点嘴炮,输赢都是无所谓的。你带着目的来,这就不同了,你赢了输了,都和你宣传的 GA 隐性的关联上了。 我看了你的这些推广,没有去 GitHub 点 star ,也没有用 GA ,就不是智力正常的人了? @h4nru1 #66 |
 |
68
momocraft 53 mins ago
味儿大 已经不像起号的了 像反串黑的
|