Transformer 没有一个"离散、可验证、逐步更新"的状态来维护计数。
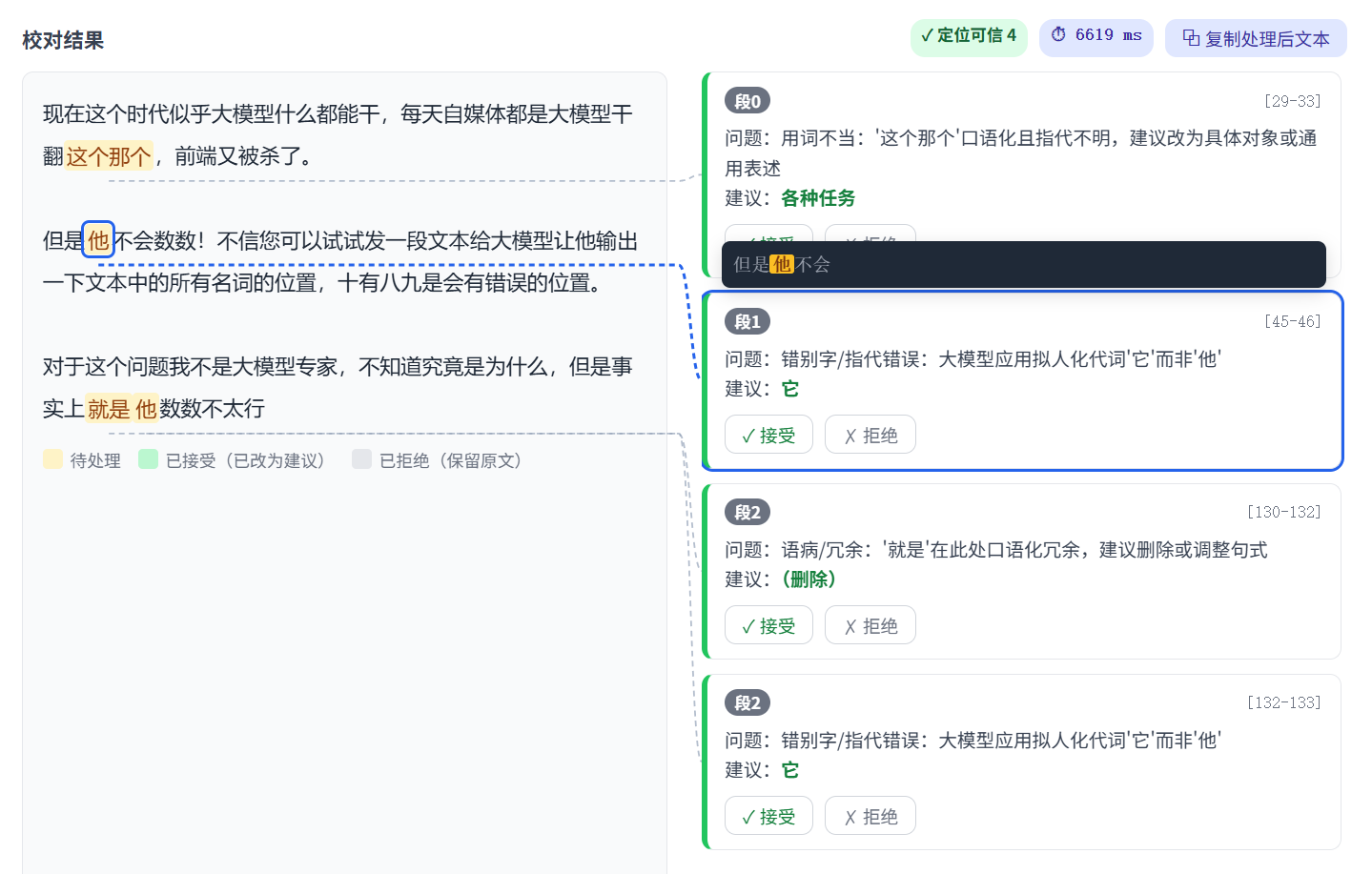
现在这个时代似乎大模型什么都能干,每天自媒体都是大模型干翻这个那个,前端又被杀了。
但是他不会数数!不信您可以试试发一段文本给大模型让他输出一下文本中的所有名词的位置,十有八九是会有错误的位置。
对于这个问题我不是大模型专家,不知道究竟是为什么,但是事实上就是他数数不太行
如何解决这个问题?
但是有些场景是依赖大模型输出对应的下标的,这似乎又是必须依赖大模型数数了。
例如利用大模型标记文档中的所有写错了的文字。
既然直接数数不行,但是如果你让大模型去复述文本却能得到很高的准确率。
那么自然而然的就能想到,将文本先按字拆分,然后将下标和文字一起给大模型,例如 : 1:大 2:模 3:型 4:不 5:会 6:数 7:数 这样之后输出的下标准确率就会飙升。
下面是一个简单的尝试,显而易见的 带坐标输入 的方案准确率更好

更好的解决方案
在经过一段时间的尝试和摸索之后,我发现就是结合文本分段,再加上一个上下文的一个后期的坐标修正是能够达到最佳的一个体验的。
例如给每一个段落分配一个 id 交给大模型,并且让他输出的时候携带相关文本前面一段文本和后面一段文本,输出示例: {before:'交给',target:'大模型',after:',并且',snippet:'片段 id'}
这样基本能达到 95% 以上的准确率了。
上面是一些拙见,欢迎指正交流更好的方案
实际应用场景,文档校对 demo 演示: