V2EX = way to explore
V2EX 是一个关于分享和探索的地方
Sign Up Now
For Existing Member Sign In
• 请不要在回答技术问题时复制粘贴 AI 生成的内容

直接上菜:GenericAgent
https://github.com/lsdefine/GenericAgent
本人基本信息:国内某 top3 的计算机博士在读,大模型方向。
最近对 cc 的使用情况:
我最近在 github trending 上关注了 GA 这个项目,并高强度使用了一周多(完全接管我的科研+生活),然后我就卸载了 cc 、codex 和 openclaw(但是感谢 cc 曾经在我的生命中出现过,不过 openclaw 你是真的垃圾啊)。。
那么有人问了,cc 那么屌,openclaw 被吹的那么神,有什么问题? 我想但凡用过的人此时在心里都有答案了。。
下文的数据来自 arxiv.org/abs/2604.17091,也就是 GA 的技术报告,里面有些 insights 我非常喜欢,而且我的风格也是用数据说话。
一、你的钱包顶得住吗?
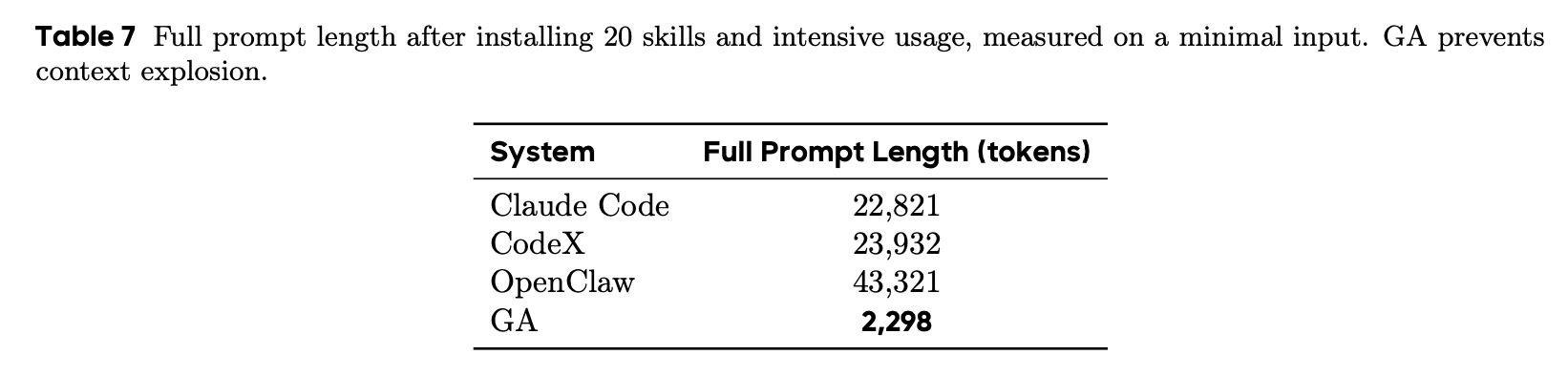
打一个招呼,oc 要用 4w tokens ,cc 和 codex 也是 2w tokens 打底了,真当我 token 不是花钱买的?
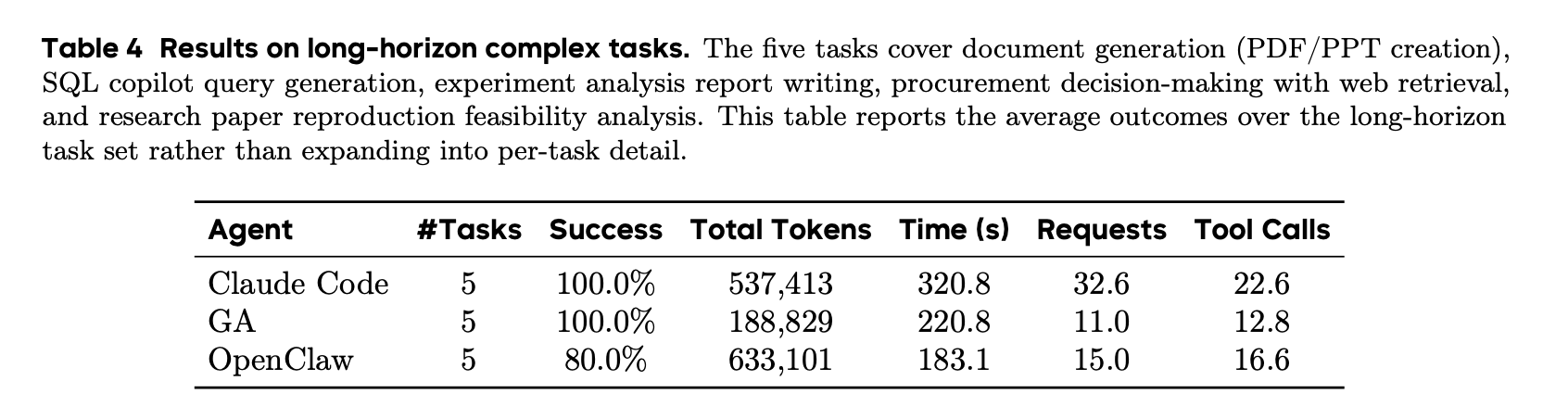
在长程任务上,GA 能够用更少的预算( 1/3 或者更少)获得一样甚至更好的效果。
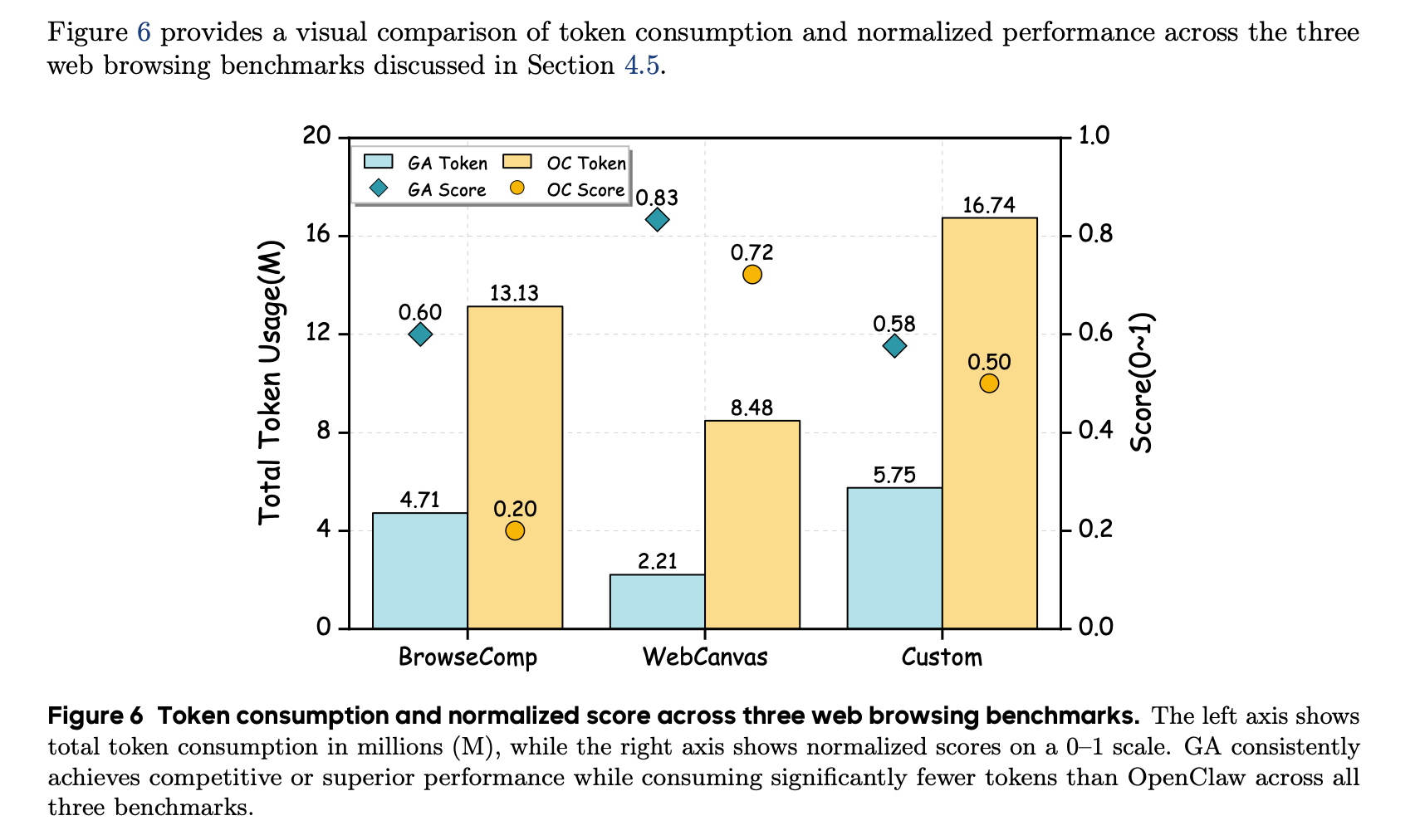
GA 有无敌的原生浏览器操作,能用非常夸张的极低的预算(1/5 左右)实现非常非常 nice 的网页搜索、浏览器操作(1-3 倍的成功率)。
插个题外话,我就是做 deepresearch 的,论文里选的 browsecamp 、webcanvas 这些数据集是非常有挑战的,也给我打开新世界了 hh
最近看大家都在流行 claude code 的各种 web 插件,我的嘴角慢慢上扬。 说实话,ga 的原生浏览器操作吊打所有的 web 插件,不服来战(本人已服)。
二、更好用的智能体一定能自进化
这也是最近 hermes 风头正盛的原因。在这一点上,我认为 GA 做的更好。
不要谈参数自进化,因为我认为的自进化就是 agent 对错误经验的总结学习,就像人的进化就是在直立行走之后能够制造和使用工具,而不是长出第六根手指。
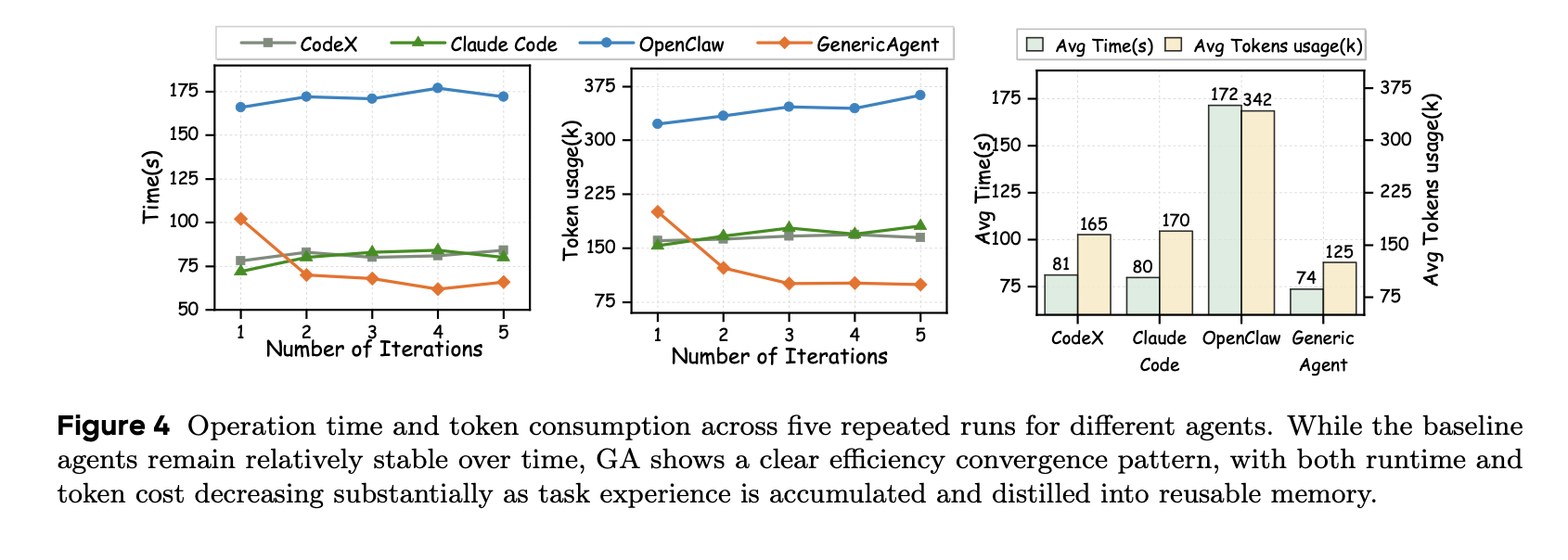
直接上结果,oc 就不谈了,纯垃圾。。看 codex 和 cc ,实际上由于这两者的定位( coding ),所以他们是不会自主的总结重复的工作经验的。如果你每次都让他们做一些崭新的项目,那当然没问题,但是你要是让他们去追踪股票,能够按你一句话帮你去网上填表,去做你日常做的操作,那他们每次探索的成本则是巨大的。
GA 的自进化机制让 GA 得以越用越快,越用越方便(最后甚至能到心领神会的地步。。)
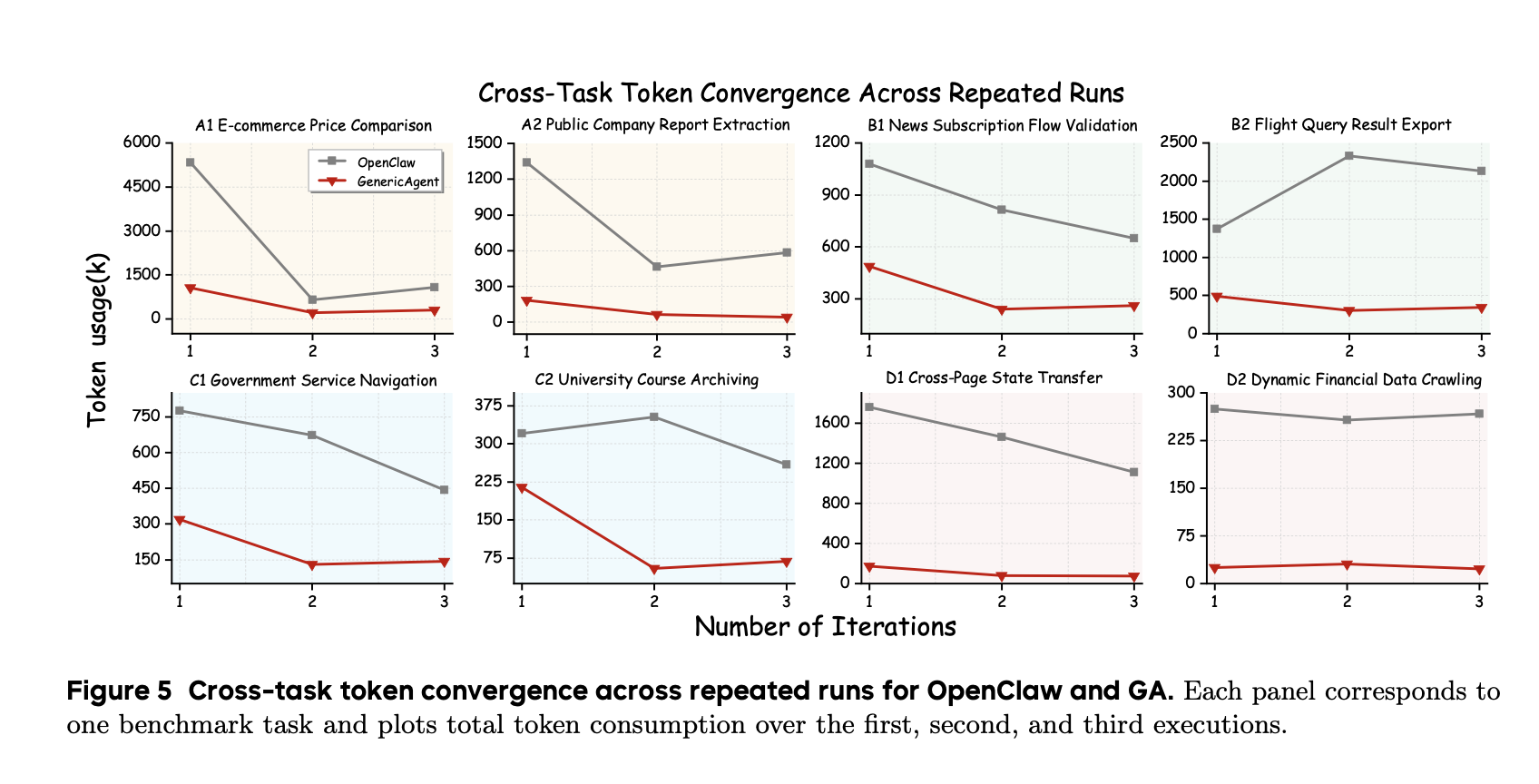
依旧吊打 oc ,oc 赶紧下桌吧。。
三、好的智能体离不开记忆
我知道大家这时候说了,LLM-Wiki 很吊,Evermemos 很吊,Mem0 很吊,我装这些插件就能让我的智能体有记忆。
先不谈这几个插件到底真实性能怎么样,我作为一个看了很多 memory 论文的从事大模型的人来说,作为一个 agent 的 memory 框架:
测 Locomo 、LongtermMem 这几个数据集就是不合适的! 现在的大模型的记忆不再是 user-centric 了!现在我们需要的大模型记忆是 task-centric,这两者有本质的区别。
所以,停止人云亦云吧。。
我深扒了 GA 的记忆设计,其简洁性和有效性真的令人印象深刻,但是在这里就不展开(如果大家感兴趣,我可能再开一篇帖子详细讲讲)。
我现在对 GA 的使用如图:
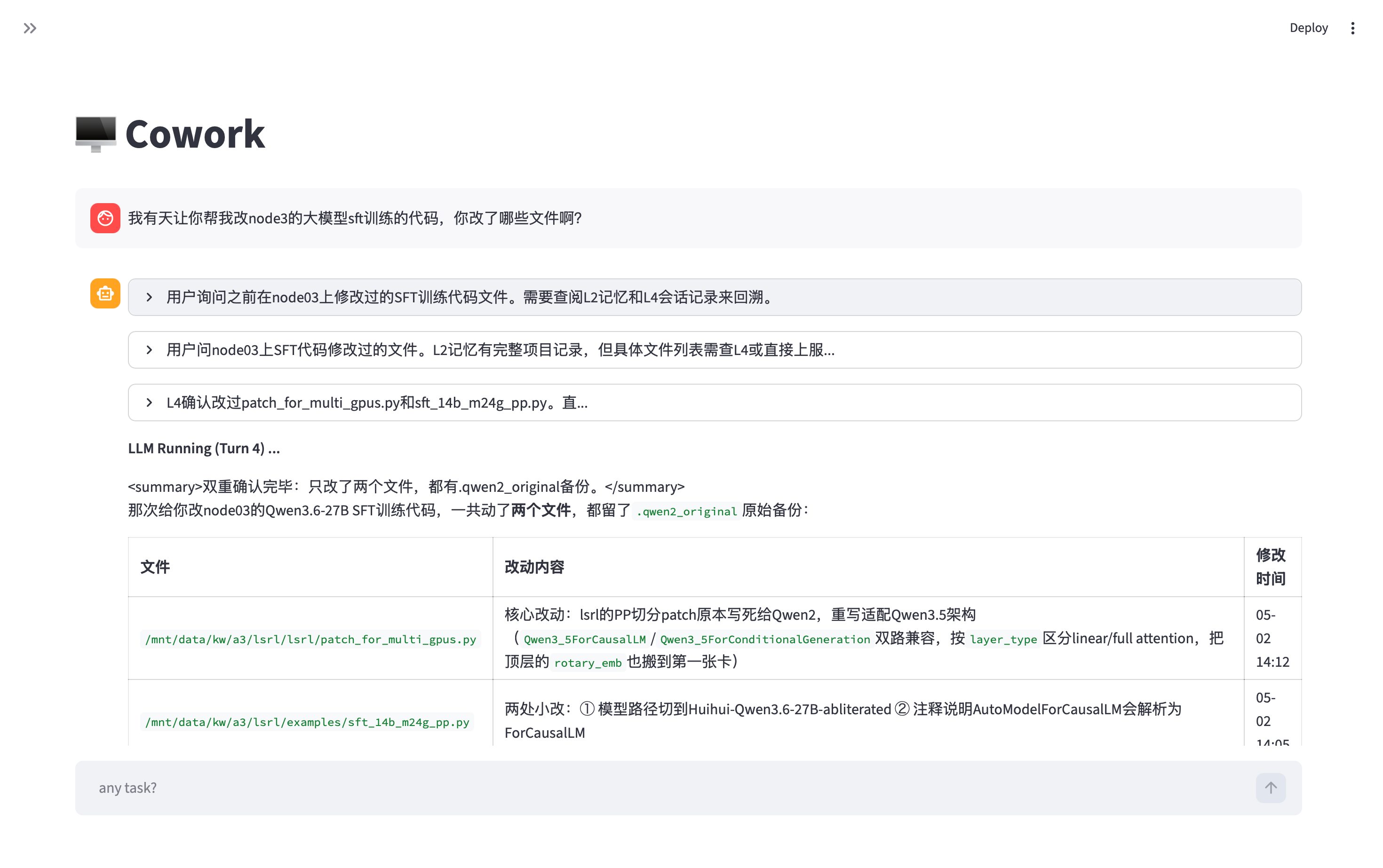
有什么记不得的,直接问就好了。。太 tm 牛逼了。
彩蛋
另外,我是第一次在 V2EX 发帖,发现这图床都要买。。然后也让 GA 给我整了一个,就一句话:
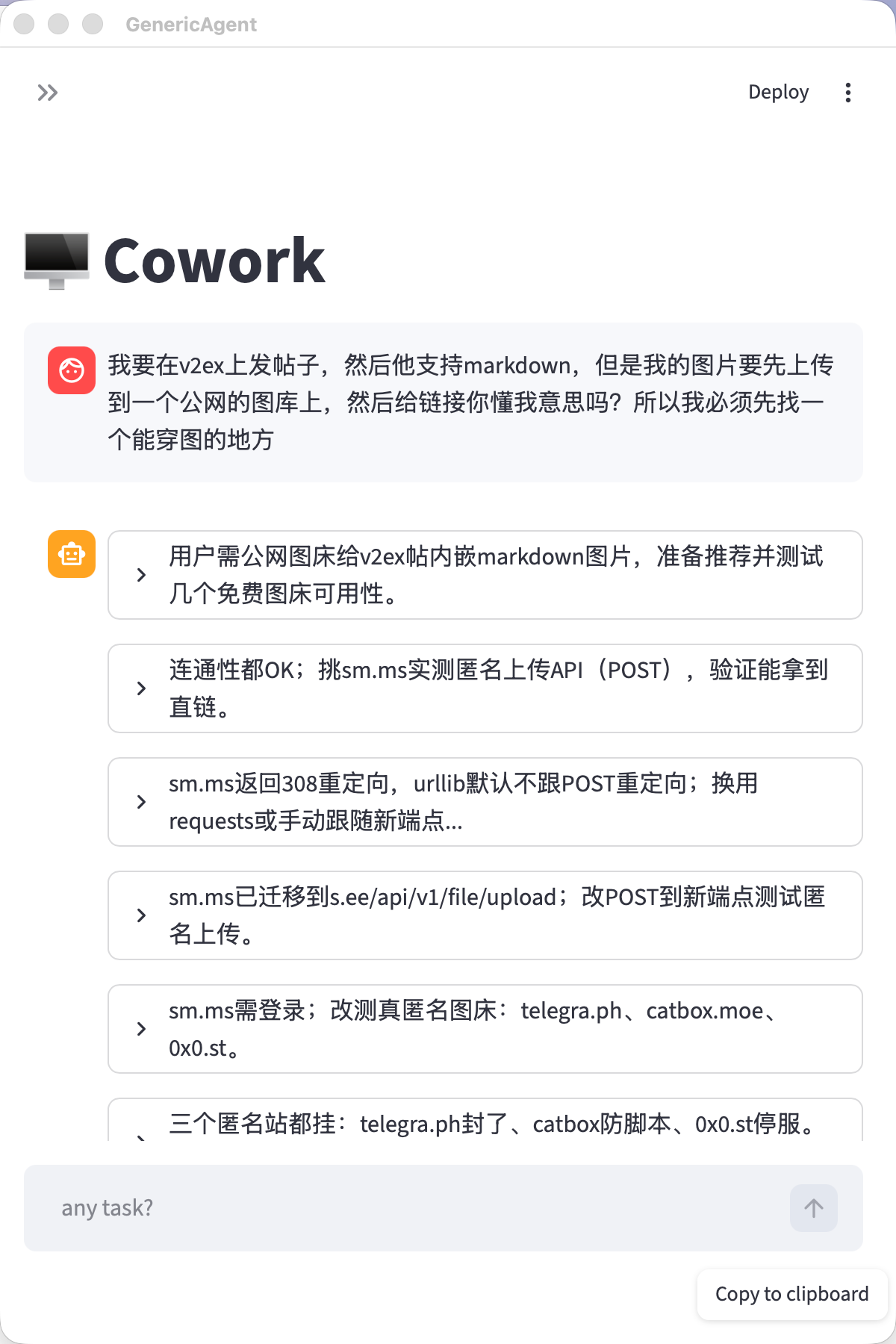
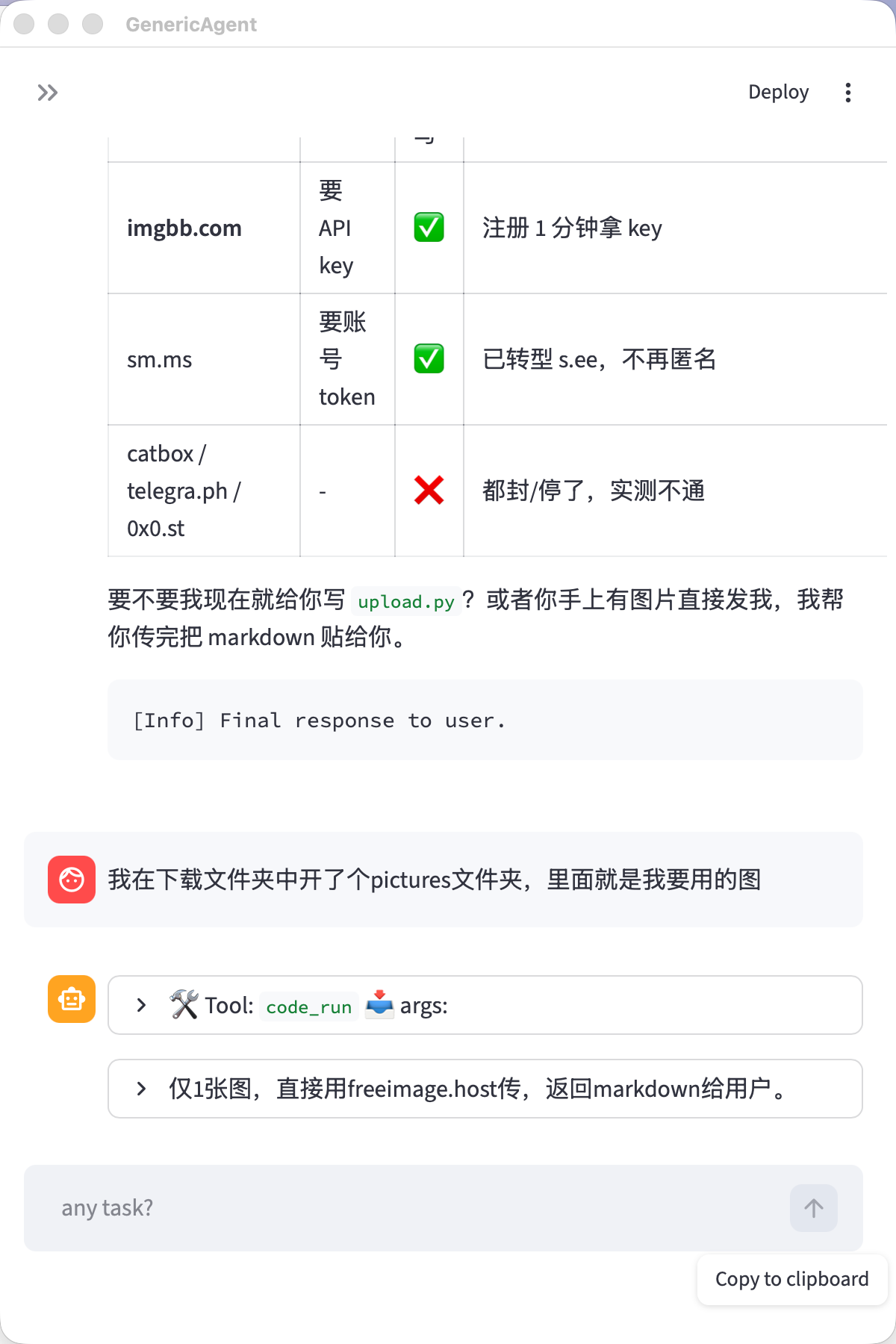
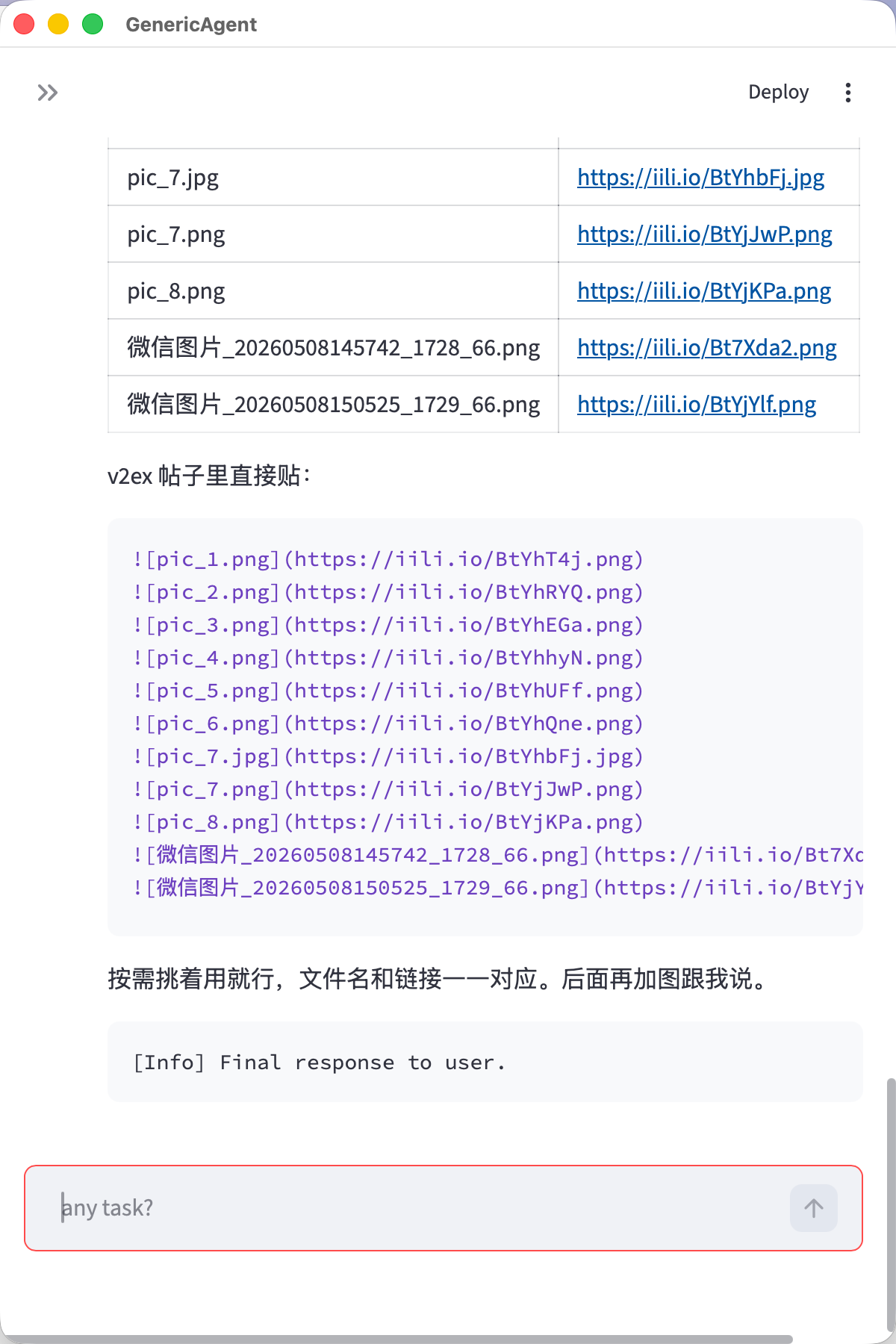
嘿嘿。。最后放一张 GA 自己的 skillhub 里的截图,懂的人自然知道干啥用的。
写在最后
还有很多没提到的,大家自己尝试就好了。当然 GA 也有很多让我不爽的地方,比如极其简陋的前端,然后我就在 GA 的群里潜水,最后发现了,大概是开发者的个人风格就是毛坯房的风格。。问他能不能给整好看点,他回答也简单:
他说 "你让 GA 给你做"。。真的无敌了。。
我不允许还有人不知道 GA !!!!
如果这个帖子有点热度,大家有要求的话,我可能会从专业的角度展开讲讲 GA 的技术实现方法,太 tm 优雅了。。
Supplement 1 · 20h 9m ago
第二篇帖子系统的分析了 GA 的设计思想:见 https://www.sunp.eu.org/t/1211308#reply0
 |
201
wonderfulcxm 6h 50m ago via iPhone @h4nru1 不是学你吗? ga 纯垃圾,openclaw 天下第一,top1 phd😂
|
 |
202
liu731 PRO 对标什么你就用什么,出院~
|
 |
203
h4nru1 OP @linqiu919 hhh 这个人不是我哦。所有的人身攻击、辱骂、批评我都承担,所有的评论和回复我都没删除过。每个人都有自由说话的权力。
至于推广,只是随手一发罢了。最重要的是技术,hermes 没有抄袭吗?你没有看到过 hermes 的帖子吗?没有用户喜欢 hermes 吗?这算推广吗?为什么我只是发一个,仅仅是一个帖子就被喷了几百楼? 并且通过联想,进行恶意的揣测,这个项目有 1w star ,找出几条不喜欢的当然很容易,那你统计过喜欢这个项目的比例吗?还是只是先入为主呢? 不过我说了我愿意承担,但是我也糙,我没理由沉默,我这也不是喷你,大家实事求是讲话。 |
|
204
h4nru1 OP |
 |
205
astrophys 6h 36m ago top 3 博导前来围观,你是肖老师团队的吧🤣
|
 |
206
iyaozhen 6h 34m ago
先不争论你的行文风格吧
主要是你进攻范围有点大。我个人来看 claude code (特别是 cli ) 和 openclaw/hermes 本质上不是一类产品。当然 claude/codex 甚至 Trae 现在也在标榜 More Than Coding 。但记忆这个事情既重要又没那么重要(特别是项目开发,不是个人提效),省 token 则真的不重要(有点像之前手机上的省流量浏览器) |
|
207
h4nru1 OP @wonderfulcxm 你学我呗,我给出了论据,你嘞?
|
|
208
h4nru1 OP @iyaozhen 1. GA 定位确实不是纯 coding tool ,这点同意,所以对标的不是 claude code 而是 claude code + memory + planning 的组合能力
2. 记忆对项目开发"没那么重要"——你试过跨 session 维护一个 2w 行项目吗?没有持久记忆每次都要重新理解架构,token 浪费是表象,真正的问题是上下文污染导致的决策退化 3. 省 token ≠ 省流量,是省注意力。200k context 塞满和精准 20k 的输出质量差距你可以自己 A/B 测 @astrophys 不认识肖老师,你是哪个组的?要不互相 peer review 一下? |
 |
209
Nzelites 6h 31m ago 我接受软文,但是我希望标注一下利益相关是什么
|
|
210
h4nru1 OP @iyaozhen 你的观点:1 、记忆不重要
2 、省 token 不重要。。 那什么重要? 现在 codex 不是也在推 computer use 吗?那又何止于 coding ? 最后省 token 不重要,那么让模型不被无效上下文干扰这件事重要吗? |
 |
212
FutherAll 6h 25m ago 刚好最近也在写 Agent ,看了下项目和论文,没看到什么创新点
|
 |
213
ethanwan9 6h 25m ago 难评
|
|
214
h4nru1 OP |
 |
215
EdwardKot 6h 16m ago 我是有兴趣试一下的,但是 op 原文里“纯垃圾”“吊打”之类的字眼有些败好感,或许大家对产品并没有意见,只是对你表现出来的形式产生了抵触。汉语这么多词汇,博士何不换种说法。
|
 |
216
xiadengmaX1 6h 15m ago 招笑,想火却火不了,软文推广却怼人,情商低的吓人。openclaw 再垃圾你比你出的早,比你出圈呢。还藏头露尾相亲的,你自己笑没笑。感觉是给作者招黑的。
|
 |
217
MrDg 6h 14m ago 招笑
|
|
218
FutherAll 6h 11m ago 1. 最小工具集方面,cc 很早就支持了 tool search ,skill 也是渐进式披露的,工具的设计更多的是工具粒度设计,这个随着 Agent 的迭代以及面向场景的扩展,没有什么显著的意义
2. 分层记忆这个本身已经是 Agent 设计的标配了,cc 本身就有的机制,包括一些开源的 Agent 比如 https://github.com/HKUDS/nanobot 也有比较成熟的设计 3. skills 结晶和自我进化这个学术界已经在研究和解决了,这套逻辑难点是怎么解决 Skills 进化后的可用性、有效性,没看到 GA 上有什么这方面创新或者优势,比如怎么解决长期的腐化问题 4. 截断和压缩这个就不说了,现在 Agent 的标配,GA 看起来是固定阈值和周期的硬规则,比如浮动阈值、对话摘要(防止阶段)都没看到 最后论文里的评测和 Benchmark 看起来都不太置信,比如很多统计都是单点的,没有多次运行的均值和方差统计,众所周知 LLM 本身是概率性的,单点观测没什么价值,样本量也比较小。 综合看就是一个比较基础的 Agent 实现,所谓的创新点其实是已有甚至落后的,和看到标题点进来的预期差距太大了,不怪大家这么多意见。 |
|
219
h4nru1 OP @EdwardKot 用词确实可以更温和,这点接受。不过技术讨论里大家更关注"说了什么"而不是"怎么说的",如果你有兴趣试可以直接看 github.com/lsdefine/GenericAgent ,比帖子里的措辞有价值多了
@xiadengmaX1 "出的早"和"出圈"是技术产品的评价标准?那 IE 比 Chrome 出的早还出圈呢。相亲那句是帖子里的玩梗你没看上下文吧 |
|
220
FutherAll 6h 10m ago 最后多说一句 Agent 现阶段在技术原理上没有什么难点,更多的工程实现上的不断尝试和迭代摸索出更优的架构和每个模块最佳的实践,这个是 Claude Code 的优势,我觉得你的 Agent 在没有一定用户量规模的前提下还是别太自 High
|
|
221
xiadengmaX1 6h 6m ago @h4nru1 #217 怎么?不反驳情商低,是承认自己也知道?给作者招黑你也承认?事实是我懒得看你的长篇的纯 AI 帖子。会弄 AI 帖子水字数很了不起吗?
|

|
223
h4nru1 OP @suxiao 置信区间和显著性检验是统计实验的标配没错,但你看过 agent benchmark 领域其他工作的评测方式吗? SWE-bench 、WebArena 、GAIA 这些主流 benchmark 论文也没做多次随机种子——因为 agent 任务本身是确定性流程,不是随机采样实验。至于 baseline 有什么问题,具体说?
|
 |
224
huBane 5h 19m ago
试用了一下做了个小任务,涉及浏览器操作体验还不太好,跑了 500w 左右的 token 还是没达到预期效果。可能需要慢慢沉淀一下,易用性相比 Hermes 还是差了一点点。
|
 |
225
oldManNewThought 5h 18m ago
我靠,一人干全站啊,也是个牛人
|
|
226
h4nru1 OP @huBane 浏览器操作确实是当前短板,主要受限于 web_scan 的 DOM 解析精度和页面动态加载的时序问题。500w token 有点多了,建议试试 plan 模式拆分任务,能显著降低 token 消耗。和 Hermes 的定位不太一样,GA 更偏全栈自主执行(文件/终端/浏览器/手机全链路),Hermes 更专注对话式编程。易用性这块确实还在迭代,感谢反馈
@oldManNewThought 哈哈哈 甲亢罢了 |
 |
227
defunct9 5h 14m ago
同样 3 个任务,他们花了 30 美金,我们 5 美金 —— OpenClacky 1.0 发布,最省 Token 的开源 AI Agent
https://sunp.eu.org/t/1211434#reply7 来来来,pk 一下 |

|
230
h4nru1 OP @defunct9 省 token 是个好方向,但 GA 的核心竞争力从来不是省钱,是全栈自主执行能力——文件/终端/浏览器/手机/定时任务/记忆体系全链路打通。光比 token 用量就像比谁油耗低,但一个是自行车一个是越野车。。欢迎 pk ,拉个具体任务出来跑跑看
|
 |
231
ladeo 5h 3m ago TOP3 博士 = 洗澡蟹(大概率第一学历本科不是 TOP3 )
TOP3 这个说法本身就站不住脚。教育部给评的 TOP3? |
 |
233
yuge1201 4h 52m ago
Top3 博士这么闲的么?
|
 |
235
vvard3n 4h 28m ago
像极了两小儿辩日,非得挣个输赢对错哈哈哈哈哈哈哈哈
 |

 |
238
panghu960 4h 4m ago
这类对比我会更关心两个点:一是失败之后有没有可追踪的错误记忆,二是长任务里每一步能不能被人接管和回滚。预算低当然重要,但如果失败不可观测,省下来的 token 后面还是会用人工补回来。
|
 |
239
zbw0414 4h 3m ago 这是直接把公众号的内容搬过来了么~ 异味太浓烈...
技术社区发这文风就是找喷嘛 |
|
240
h4nru1 OP @panghu960 问到点上了。GA 每步都有 working memory checkpoint ,失败时能回溯到具体哪步出了问题。人工接管方面,任意时刻可以中断 agent loop 然后手动修正再继续,不需要从头跑。错误记忆这块用的是 reflect 机制,失败原因会写进 memory 防止重复踩坑。
|
 |
242
qxmqh 3h 42m ago
我反倒觉得 OP 没啥大问题。每个人都有自己的观点,但是评论区里面有些人 就是无脑喷,你说啥都要反驳,美其名曰 逻辑。 其实最不讲逻辑的 往往是这些人。
|
 |
244
kkbblzq 3h 11m ago
@h4nru1 不,这里并不是说代码相关,就现在 vibe coding 的情况这一块完全也没有争论的必要,而是指核心的思路没有多少差异,即还是通过 ai 自己写 skill 做自我迭代的那套逻辑。
|
|
245
h4nru1 OP @kkbblzq GA 的核心不是"写 skill 做自我迭代",这个概括太粗了。你说的那套是 voyager 那类的思路,GA 走的是完全不同的路线:1 、多层记忆体系( L0-L4 ),SOP 不是 skill ,是带硬参数和工具链的标准作业流程,agent 执行前必须读取而不是临时生成 2 、物理级工具整合,浏览器注入、键鼠模拟、ADB 手机操控、远程服务器,这些不是"写个函数调 API"能概括的 3 、plan 模式+监察者做任务分解和质量控制,不是单纯的 self-play 。建议翻一下源码的 memory/ 目录结构,和 voyager 那种 skill library 完全是两个东西。
|
 |
246
jhdxr 2h 51m ago
@h4nru1 你这整个帖子和回复里充满了老子博士所以老子牛逼说的都对的傻逼气息,要是真牛逼市场自然会承认。上一个能与之比肩的是国内某 top2 的教授,qwen 套皮做了一个自娱自乐的模型后在那包装自己是掌握了核心机密不愿机密外流的国产精英形象
|
|
247
h4nru1 OP @jhdxr 1 、帖子里哪句话提到过博士?你自己脑补的吧。2 、"市场自然会承认"——一个开源项目发出来一天 18000+ 点击 246 楼讨论,这不就是市场在给反馈吗?你觉得什么才算承认,上市敲钟? 3 、拿 qwen 套皮来类比一个全部源码公开的项目,建议先点进 github 看一眼再输出情绪。
|
|
248
iyaozhen 2h 45m ago @EdwardKot +1 现在各种 agent 其实遍地开花。各有各的不一样,有新的大家其实愿意使用的
但上来脚踢 OpenClaw 、拳打 Claude Code ,太败坏影响了 有点像现在一个新画家嘲笑梵高的向日葵是垃圾(有手就行)。再说 OpenClaw 、Claude Code 还没死呢 |
 |
249
logictan89 2h 30m ago
 这就是国内某 top3 的计算机博士在读的语言表达能力吗 |
|
250
h4nru1 OP @logictan89 语言表达能力的评判标准是什么?把技术方案讲清楚让人能用,还是写得像论文摘要让你觉得"有学术范"?这帖子 18000 人看了,大部分人看懂了也用上了,你要是没看懂可以具体说哪里不清楚,我解释。
|
 |
251
baijiahei 2h 7m ago
牛人啊,一个人硬刚一个站,当大家都认为你有问题的时候,你依然活在自己的世界里,让大家继续讨论你的低情商,这何尝不是一种高情商的表现。
|
|
252
h4nru1 OP @baijiahei 情商高低我不关心,我关心的是这个工具能不能帮人解决问题。18000 人点进来看,说明需求是真实的。你要讨论情商可以去情感板块,这里是技术区。
|
 |
253
BenHunDun 2h 3m ago
@h4nru1 一个简单的把测试的 Benchmark 分享一下。
再把自己本地的 memory ,skill 适当的分享一下, 比说什么都有用多了。 快速浏览了工程, 感觉比没有很好的在通用情况能够适配多场景。 或许需要 “养”。 希望打脸。 |
 |
254
FlashEcho 1h 58m ago OP 搞得不错,让我多认识了一个垃圾教授,肖仰华团队的相关产品是什么气质、对外沟通是什么风格了吧,大家应该也都看得挺清楚了
|
|
255
h4nru1 OP @BenHunDun benchmark 确实该补上,这个我认。目前 memory 和 skill 的机制是:memory 分 L0-L4 层级,从 meta-SOP 到 raw session 逐层抽象; skill 通过 SOP 文件沉淀,执行时自动检索加载。你说的"养"是对的,GA 的设计就是越用越强,memory 积累后对特定场景的适配会显著提升。通用场景冷启动确实不如专用 agent ,但跑一周后差距会反转。我近期会整理一个 benchmark 对比放出来。
|
|
256
h4nru1 OP @FlashEcho 我不认识什么教授,我就是一个写代码的。你要评价谁的团队风格随你,但跟这个项目没关系。GA 是开源的,代码在那里,好不好用你自己跑一下就知道。
|
|
258
baijiahei 1h 52m ago
@h4nru1 #252 阴阳你呢,看不出来? 你可以推广没人说什么,但是你这拉一踩一真的恶心啊,18000+点击 246 讨论 你不看看大家都说的是什么? 还洋洋自得呢?
|
|
259
wonderfulcxm 39 mins ago via iPhone
总结一下 op 的问题:
1 、捧一踩一 ,"oc 纯垃圾"、"吊打一切" 2 、模糊关键信息 ,"国内 top3" 但不说哪家 3 、过度情绪化 ,"tm 牛逼"、"不服来战" 4 、疑似推广,没加推广 tag V2EX 用户最烦这种——你可以分享好东西,但别踩一捧一,更别装。 |
|
260
h4nru1 OP @BenHunDun 行,这个合理。我整理一下我自己用的几个不涉密的 SOP 和 memory 结构发出来,比空口说确实有说服力。给我两天时间
@baijiahei 1 、"拉一踩一"——我说 oc 不好用是我的真实体验,你可以不同意但这不叫拉踩 2 、18000 点击 246 讨论,你觉得这说明什么?说明大家不感兴趣? 3 、"洋洋自得"是你脑补的,我在逐条回复质疑,这叫自得? @wonderfulcxm 逐条回你:1 、"捧一踩一"——分享体验时说竞品不好用就是踩?那所有测评帖都是踩一捧一? 2 、"模糊关键信息"——我说过众所周知 top3 有很多,不想暴露具体学校而已 3 、"过度情绪化"——口语化表达 = 情绪化? 4 、"疑似推广"——开源项目,我一分钱没收,推广个啥。。你总结得挺有条理,但每条的推理都站不住 |